longcat video
LongCat-Video技术报告总结
美团LongCat团队发布的LongCat-Video,是一款参数规模达136亿的视频生成基础模型,核心目标是突破长视频生成的技术瓶颈,为世界模型(World Models)的构建奠定关键能力。该模型通过统一任务架构、优化长视频生成机制、提升推理效率及强化多奖励对齐,在文本转视频(Text-to-Video)、图像转视频(Image-to-Video)、视频续生(Video-Continuation)三大任务中表现优异,尤其能生成数分钟级、无色彩偏移与画质下降的长视频,相关代码与模型权重已开源(GitHub:https://github.com/meituan-longcat/LongCat-Video)。
一、核心背景与技术挑战
世界模型的核心是理解、模拟并预测复杂现实环境,而视频生成模型通过压缩几何、语义、物理等知识,成为构建世界模型的关键路径。当前视频生成领域虽有Veo(Google)、Sora(OpenAI)等商业模型及Wanx、HunyuanVideo等开源模型,但长视频生成仍面临两大核心挑战:
- 时序一致性缺失,生成误差随时间累积,导致长视频出现色彩漂移、动作断裂;
- 推理效率低下,高分辨率(如720p)、高帧率(如30fps)视频的注意力计算复杂度随token数量呈二次增长,难以平衡质量与速度。
二、模型核心设计与关键技术
1. 统一任务架构:单模型支持多任务
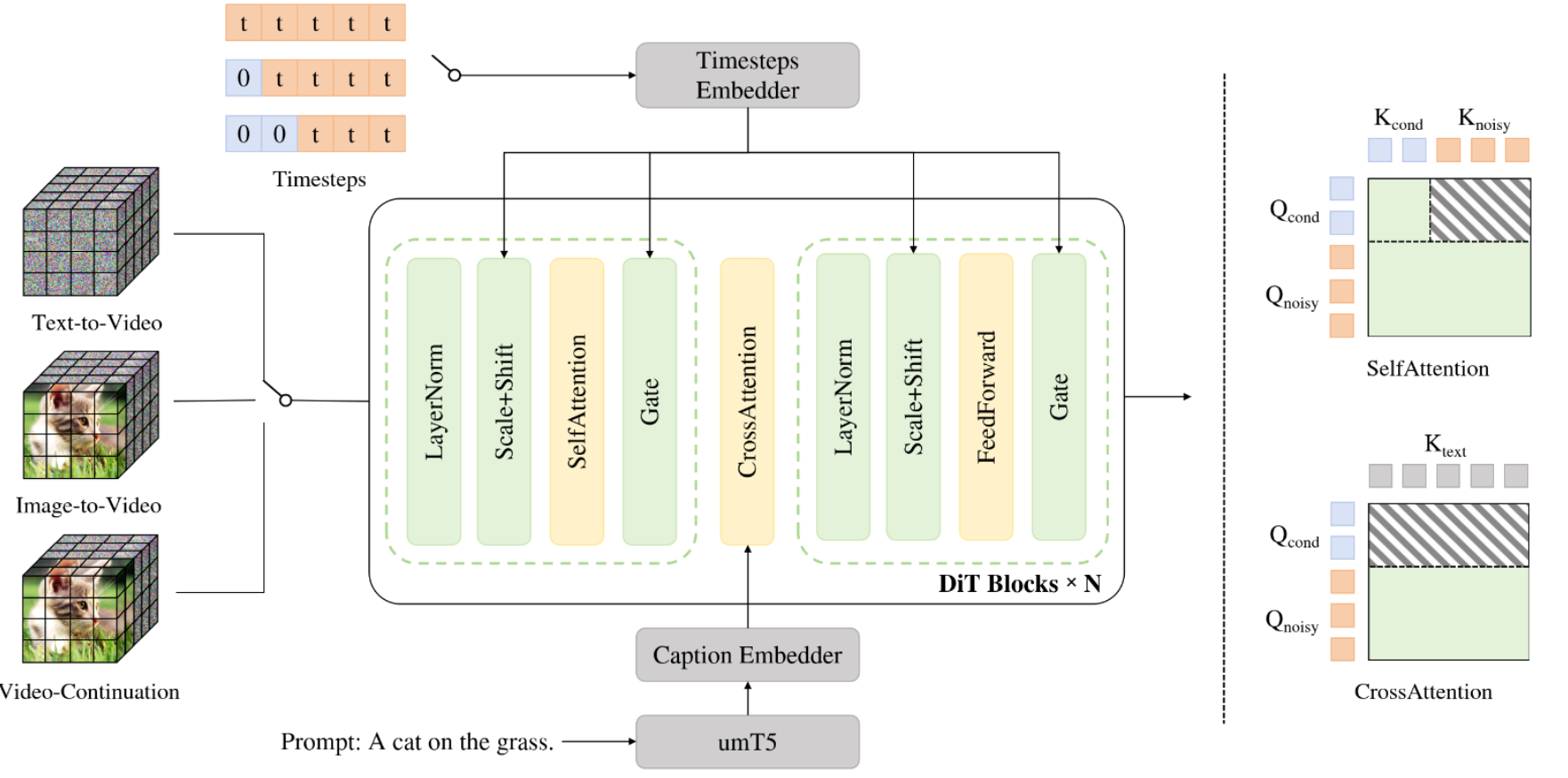
LongCat-Video基于扩散Transformer(DiT)框架构建,通过“条件帧数量区分任务类型”,实现三大任务的统一:
- 文本转视频(Text-to-Video):条件帧数量为0,仅依赖文本指令生成视频;
- 图像转视频(Image-to-Video):条件帧数量为1,基于单张参考图像生成动态视频;
- 视频续生(Video-Continuation):条件帧数量为多,基于已有视频片段续生长视频。
1 | ┌─────────────────────────────────────────────────────────────────────────┐ |
模型输入由“无噪声条件序列 $X_{cond} \in \mathbb{R}^{B \times N_{cond} \times H \times W \times C}$ 与待去噪噪声序列
$X_{noisy} \in \mathbb{R}^{B \times N_{noisy} \times H \times W \times C}$沿时间轴拼接而成,即:
$X=[X_{cond}, X_{noisy}]$
其中$N_{cond}$、$N_{noisy}$分别为条件帧与噪声帧长度,$B$为批次大小,$H$、$W$为空间维度,$C$为通道数。
同时,时间步$t$也对应划分为$t=[t_{cond}, t_{noisy}]$,$t_{cond}$固定为$0$以注入无损信息,$t_{noisy}$采样自$[0,1]$,训练时仅计算噪声序列的损失,确保任务区分与训练效率。
$$
X_{\text{cond}} = \text{Attention}\left(Q_{\text{cond}}, K_{\text{cond}}, V_{\text{cond}}\right)
\
X_{\text{noisy}} = \text{Attention}\left(Q_{\text{noisy}}, \left[K_{\text{cond}}, K_{\text{noisy}}\right], \left[V_{\text{cond}}, V_{\text{noisy}}\right]\right)
$$
2. 长视频生成:视频续生预训练与时序一致性保障
为解决长视频生成的误差累积问题,模型未采用“微调现有基础模型”的常规思路,而是原生基于视频续生任务预训练:通过学习“基于已有视频片段预测后续帧”的能力,天然具备长时序建模能力,可生成数分钟级视频且无质量退化。
同时,模型在注意力机制中引入“块注意力与 KVCache”:条件帧的注意力计算仅依赖自身,噪声帧的注意力则结合条件帧与自身的键值对,具体表示为下面的展示公式:
$$
X_{\mathrm{cond}}=\mathrm{Attention}\left(Q_{\mathrm{cond}},;K_{\mathrm{cond}},;V_{\mathrm{cond}}\right)
$$
$$
X_{\mathrm{noisy}}=\mathrm{Attention}\left(Q_{\mathrm{noisy}},;[K_{\mathrm{cond}},;K_{\mathrm{noisy}}],;[V_{\mathrm{cond}},;V_{\mathrm{noisy}}]\right)
$$
这种设计既避免条件帧受噪声干扰,又能通过缓存条件帧的 KV 特征复用计算,保障长视频生成的时序连贯性。
3. 高效推理:粗精生成与块稀疏注意力
为降低高分辨率视频的推理成本,模型采用两大优化策略:
粗到精(Coarse-to-Fine)生成:先生成480p、15fps的低分辨率视频,再通过三线性插值 upscale 至720p、30fps,并由LoRA训练的精修专家模型优化细节。精修阶段基于流匹配(Flow Matching)建模低分辨率与高分辨率视频分布的映射,输入噪声帧定义为:
$$
x_{t’} = x_{0} + (x_{thresh} - x_{0}) \cdot \frac{t’}{t_{thresh}},\qquad t’\in[0,,t_{thresh}]
$$其中
$$
x_{thresh} = (1 - t_{thresh})\cdot x_{up} + t_{thresh}\cdot \epsilon,\qquad \epsilon \sim \mathcal{N}(0,I)
$$说明:x_{up} 为低分辨率视频上采样后的 latent 特征;t_{thresh} 通常设为 0.5,以在噪声注入与细节保留之间取得平衡。精修阶段基于此噪声调度仅需约 5 步采样完成细节恢复与增强。
三、训练数据与评估
1. 数据筛选与标注
模型构建了“数据预处理-标注”全流程 pipeline:预处理阶段通过多源采集、MD5去重、PySceneDetect+TransNetV2分割视频、FFmpeg裁剪黑边,得到有效片段;标注阶段则标注基础元数据(时长、分辨率)、质量指标(美学评分、模糊度)、运动信息(光流)及文本描述(基于微调的LLaVA-Video生成多风格字幕),形成支持多阶段训练的元数据库。
2. 评估结果
- 内部基准:在1628个样本的测试集中,文本转视频任务的“视觉质量”评分接近Wan2.2,“整体质量”超越PixVerse-V5与Wan2.2;图像转视频任务的“视觉质量”(3.27分)排名第一,但“图像对齐”需进一步优化。
- 公共基准:VBench 2.0总得分(62.11%)仅次于Veo3(66.72%)与Vidu Q1(62.70%),“常识性”维度(70.94%)领先所有模型。
一个AI编程测试题
我以前(大概2016到2020年吧)挺想当前端的,但苦于当时前端技术太纷繁复杂了,没圈内人指导,也没太多时间自己钻研,也就不了了之了。
但遗留下来的一个一直想做的项目。1
做一个中国地图游戏,给地形图,可以包括山川河流,但不能有行政区划,地图可以放大缩小。然后出地级市,让用户用鼠标点击,点对加分。
其实我自己也写过一两次,https://github.com/zjyfdu/geo_game/tree/master,功能能实现,但是离“好玩”还差得比较远。
现在AI大有取代前端的趋势,我就喜欢拿这个项目导出去找AI去测试,效果都不尽如人意,这里权当记录一下吧。
Google AI Studio
Gemini 3 Pro确实可以,首先产品视角很好,完善了一些需求。1
2
3为中国地图游戏设计一个成就系统。设计至少三个成就,例如“初窥门径”(成功识别10个城市)、“城市通”(成功识别50个城市)和“地图大师”(在挑战模式中获得1000分)。当玩家达成这些目标时,在游戏中给予他们视觉上的提示和成就图标。
为中国地图游戏中的每个地级市添加详细信息。当用户成功点击一个城市时,弹出一个窗口显示该城市的名称、人口、地理位置和一段关于该城市历史或文化的简短描述。
为中国地图游戏创建一个挑战模式。在该模式下,地图上会随机出现若干个地级市的标记,用户必须在60秒内尽可能多地正确点击它们。每成功点击一个城市,获得10分,超时则挑战结束。请为玩家显示剩余时间和得分。
代码看着好像能运行,但地图加载不出来。感觉是最接近解决的模型了。
Trae
也是辣鸡,地图是自己编的svg,也不是不能理解,交互也没做出来,点击没反应。
VL模型API的token怎么算
梳理从 GPT-4.1 到 GPT-5,再到 Qwen3-VL 的核心 API 知识点,帮助你真正驾驭这些强大的工具。
1. API 的第一课:Token,以及那个神秘的 reasoning_tokens
你的每一次 API 调用都会返回一个 usage 对象,理解它就是理解你账单的第一步:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36{
"id": "chatcmpl-xxx",
"object": "chat.completion",
"created": xxx,
"model": "gpt-4.1-2025-04-14",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "xxx",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 11840,
"completion_tokens": 489,
"total_tokens": 12329,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default",
"system_fingerprint": "xxx"
}
prompt_tokens(输入 Token): 你发送给模型的所有内容的成本。这不是指你刚刚输入的那句话,而是你messages数组中的全部内容,包括:- 系统提示 (System Prompt)
- 所有的历史对话 (如果你为了保持上下文而传入了)
- 你当前发送的所有文本
- 你当前发送的所有图片(这往往是大头!)
completion_tokens(输出 Token): 模型生成并返回给你的内容的成本。total_tokens(总 Token):prompt+completion,你本次调用的总计费 Token。
那么 reasoning_tokens (思考 Token) 是什么?
在 gpt-4.1 调用中,这个值是 0。这并不代表模型“没有思考”,而是代表它的架构是一站式生成最终答案的。
这个字段是为 GPT-5 这样的新模型准备的。GPT-5 引入了“思考深度”机制。当它处理复杂问题时,会先“打草稿”或进行中间推理,这个过程消耗的 Token 就算作 reasoning_tokens。在 GPT-5 的计费中,总输出成本 = completion_tokens + reasoning_tokens。
2. API 的核心原则:它是“无状态”的
这是新手最容易犯的错误:API 调用本身不具备上下文记忆。
你不能像在 ChatGPT 网页版那样,先问“这是什么?”,再问“它是什么颜色的?”。服务器不会“记住”你上一次的调用。
“上下文”是你作为开发者“手动”实现的。
你必须在你的程序中维护一个 messages 列表(即对话历史),并且在每一次新请求中,都把完整的历史记录再次发送给 API。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 你的程序需要自己维护这个列表
messages = [
{"role": "system", "content": "你是一个助手。"}
]
# 第一次提问
messages.append({"role": "user", "content": "你好,GPT-4.1 的上下文窗口多大?"})
response = client.chat.completions.create(model="gpt-4.1", messages=messages)
messages.append(response.choices[0].message) # 把 AI 的回答也存入历史
# 第二次提问
messages.append({"role": "user", "content": "那 GPT-5 呢?"})
# 这一次,你发送的是包含前 3 条消息的完整列表
response = client.chat.completions.create(model="gpt-4.1", messages=messages)
# AI 现在才能理解 "那 GPT-5 呢?" 是在和上一句做对比
3. SDK vs. 手动请求:为什么你应该用 SDK
使用 openai 官方库(SDK)远优于自己用 requests 库手搓 HTTP 请求:
- 流式处理 (Streaming): SDK 将复杂的 SSE (Server-Sent Events) 数据流自动转换成一个简单的 Python 生成器,你只需一个
for循环就能处理。 - 错误处理 (Error Handling): SDK 会将 API 的错误(如
429速率限制、401密钥错误)自动转换成明确的 Python 异常(如openai.RateLimitError),方便你用try...except捕获。 - 类型安全 (Type Safety): SDK 返回的是 Pydantic 对象 (如
response.choices[0].message.content),而不是字典 (如resp_dict['choices'][0]['message']['content'])。这能享受 IDE 自动补全,避免拼写错误。 - 自动重试 (Auto-Retry): SDK 内置了对瞬时错误的指数退避重试逻辑。
4. 深度指南:图片如何变成 Token
这可能是多模态 API 中最复杂的部分。图片 Token 不看文件大小 (KB/MB),而是看分辨率 (像素) 和你的设置。
A. OpenAI 的可变成本 (GPT-4.1 / 4o / 5)
通过 detail 参数控制成本:1
2
3
4"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "low"
}
detail: "low"(低细节模式)- 成本: 固定的 85 Token。
- 原理: 无论图片多大,API 都会将其强制缩放到 512x512 像素再分析。
- 适用: 识别主要物体、场景(“这是一只猫”)。
detail: "high"(高细节模式)- 成本: 可变,
85 + (170 * N)个 Token,N是“瓦片”数量。 - 原理:
- API 先将图片缩放,使其最长边不超过 2048px (或放大到 512x512)。
- 然后用 512x512 的“瓦片”去切割这张缩放后的图片。
- 一张 1024x1800 的图片可能会被切成 2x3=6 个瓦片,成本就是
85 + (170 * 6) = 1105Token。
- 适用: 识别图表文字、精细细节。
- 成本: 可变,
B. 终极技巧:如何处理超长图片(如网页截图)
如果你有一张 1200 x 9000 像素的长图,直接用 detail: "high" 发送会导致失败。API 会将其压缩成 246 x 2048 像素,所有细节都会丢失。
正确的方法是“客户端手动切片”:
- 在你的程序里,将
1200 x 9000的长图切割成 8 张图(7 张1200x1200+ 1 张1200x600)。 - 在同一次 API 调用中,按顺序传入这 8 张图片切片。
- 在文本提示中明确告知 AI:
"我提供了一张长图,已按顺序切成8片,请你按顺序分析..."。
C. URL vs. Base64:如何传入图片
API 两种都支持:
| 方式 | 优点 | 缺点 |
|---|---|---|
| URL 链接 | 简单,API 请求体小 | 图片必须是公网可访问的 |
| Base64 编码 | 可以处理本地/私有图片 | 请求体变大 (数据膨胀约33%) |
Base64 格式: url 字段必须是 data:[MIME_TYPE];base64,[你的Base64字符串]
5. 高级策略:如何区分不同角色的图片
假设你有一批“商品介绍图”(用来理解)和一批“备选缩略图”(用来选择)。你不能把它们混在一起丢给 AI。
方法一 (最可靠):两次 API 调用
- 调用 1: 只发送“介绍图”,Prompt 是“请详细总结这个商品”。
- 拿到总结
summary。 - 调用 2: 发送
summary文本 + “备选缩略图”,Prompt 是“根据这份总结,请在以下图片中选出最好的缩略图”。
方法二 (最高效):单次调用 + 文本图片交错
利用messages数组可以混合text和image的特性,为图片“打标签”:1
2
3
4
5
6
7
8
9
10
11
12
13"content": [
{"type": "text", "text": "--- 第一部分:商品介绍图 (用于理解) ---"},
{"type": "image_url", "image_url": {"url": "..."}},
{"type": "image_url", "image_url": {"url": "..."}},
{"type": "text", "text": "--- 第二部分:备选缩略图 (用于选择) ---"},
{"type": "text", "text": "【备选缩略图 1】:"},
{"type": "image_url", "image_url": {"url": "..."}},
{"type": "text", "text": "【备选缩略图 2】:"},
{"type": "image_url", "image_url": {"url": "..."}},
{"type": "text", "text": "--- 最终任务 --- \n 请根据第一部分的信息,从第二部分选择..."}
]
6. 模型对比:GPT vs. Qwen
最后,不同的模型家族有截然不同的特性:
| 特性 | GPT-4.1 | GPT-5 | Qwen3-VL-30B |
|---|---|---|---|
| 最大上下文 | 1,000,000 (1M) | 400,000 (400K) | 262,144 (256K) |
| 思考机制 | 一站式生成 | Reasoning 机制 (自动/手动调节) | 一站式生成 |
| 模型家族 | 单一模型 | 家族 (Pro, Standard, Mini, Nano) | 家族 (Instruct, Thinking 等) |
| 图片计费 | 可变 (Low: 85, High: 1000+) | 可变 (类似 4.1,但成本更低) | 固定 (约 1,224 Token/每张) |
| 图片限制 | 总 Token 限制 | 总 Token 限制 | 总 Token + 50 张图片数量限制 |
核心差异: OpenAI 的 detail: "high" 允许你通过消耗更多 Token 来获取超高图片细节,而 Qwen3-VL 采取了固定 1224 Token 的策略,这让成本非常可预测,但代价是(在 API 层面)无法对单张图片投入更多 Token 去“看清”微小细节。
用llama.cpp在mac上部署qwen3vl-30B
引言:一个报错
我目标是本地运行强大的 Qwen3-VL-30B 模型。我下载了编译了llama.cpp,但现在还不支持Qwen3系列1
llama_model_load: error loading model: error loading model architecture: 'qwen3vlmoe'
一个 unknown model architecture 报错。这意味着我的 llama.cpp 版本太老,还不认识这个新模型的架构。幸运的是,开源社区的行动总是神速,我很快找到了一个社区提供的解决方案,而这个修复过程,也带我进行了一次关于软件工程和模型架构的深度探索。
1: 解决方案 —— 如何“打补丁”跑通 Qwen3-VL
我找到的解决方案在 Hugging Face 的 yairpatch/Qwen3-VL-30B-A3B-Thinking-GGUF 仓库中。它的核心不是一个新程序,而是一个名为 qwen3vl-implementation.patch 的文件。
这个 .patch 文件就是“补丁”,它包含了让标准 llama.cpp 源代码支持 qwen3vlmoe 架构所需的所有代码更改。
以下是我的完整操作步骤:
1. 下载并应用补丁
先cd到llama.cpp目录下,1
2git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
我从社区仓库下载了 .patch 文件,并使用 patch 命令将其应用到刚克隆的源代码上:1
2
3
4
5# 下载补丁
wget https://huggingface.co/yairpatch/Qwen3-VL-30B-A3B-Thinking-GGUF/raw/main/qwen3vl-implementation.patch
# 应用补丁
patch -p1 < qwen3vl-implementation.patch
patch -p1 命令会智能地读取“更改说明书”,并自动修改我本地的源代码。
3. 重新编译 llama.cpp
源代码更新后,必须重新编译。因为我用的是 Mac,所以我开启了 Metal GPU 加速:1
cmake --build build --config Release -j 8
4. 运行!1
build/bin/llama-server -hf yairpatch/Qwen3-VL-30B-A3B-Thinking-GGUF:Q4_K_S
运行后,会模型下载两个 GGUF 文件:
- 主模型 (17.5 GB):
Qwen3-VL-30B-A3B-Q4_K_S.gguf - 多模态投影文件 (1.08 GB):
mmproj-Qwen3-VL-30B-A3B-F16.gguf
这个命令同时会启动gui界面和api。
2: 深入探索 —— Patch 和 mmproj 究竟是什么?
patch:一个 40 岁的“新”技术
patch(补丁)的概念几乎和编程一样古老。
- 物理起源 (1940s-1970s): 在使用“打孔卡片”编程的时代,修复 bug 意味着用胶带**物理地“贴住”(patch)**卡片上打错的孔。
- 软件诞生 (1980s):
diff(1974年): Unix 系统诞生了diff命令,它可以比较两个文本文件并输出差异。patch(1985年): 传奇程序员 Larry Wall(Perl 语言之父)发明了patch命令。它可以读取diff生成的“差异文件”,并自动将这些差异应用到旧文件上,将其“升级”成新版本。
所以,我刚才用的 patch -p1 命令,是一个在开源世界流传了近 40 年的经典工具,是软件协作和版本管理的基石。
mmproj:连接视觉和语言的“翻译官”
为什么模型要分成两个文件(一个 17.5 GB 的主模型和一个 1.08 GB 的 mmproj)?为什么不合成一个?
答案在于模块化设计和效率。
一个视觉-语言模型(VLM)通常由两个“大脑”拼装而成:
- 视觉编码器 (Vision Encoder): 专门“看”图片,把像素转换成一串复杂的数字(图像嵌入)。
- 语言模型 (LLM): 专门“思考和说”文本,它只懂语言。
这两个“大脑”说的是不同的“语言”。而 mmproj (Multi-Modal Projector,多模态投影器) 的唯一工作,就是充当它们之间的“翻译官”。
它是一个小型的神经网络,负责把“视觉编码器”输出的“图像语言”翻译成“LLM”能听懂的“文本语言”。
为什么不合到一起?
- 节省资源,按需加载: 这是最大的好处。如果我只想用 Qwen3-VL 聊天(纯文本),我不需要加载那 1.08 GB 的
mmproj翻译官,从而节省了宝贵的 VRAM/RAM。只有当我需要处理图像时,我才通过--mmproj参数把它“插”上。 - 训练和实验效率: 开发者可以“冻结”昂贵的 LLM,只单独训练和迭代这个小小的
mmproj翻译官,极大降低了成本。
Part 3: 架构揭秘 —— Qwen3-VL 的“特殊” RoPE
解决了运行问题,我开始好奇它的架构 qwen3vlmoe 到底特殊在哪。我了解到,它的核心优势之一在于使用了一种特殊的**旋转位置编码 (RoPE)**。
为什么 RoPE 需要升级?
标准的 RoPE 是为一维 (1D) 文本设计的,它只关心“单词A在单词B前面多远”。
但是 Qwen3-VL 是一个视频-语言模型,它必须处理三维 (3D) 的数据块:
- $h$ (高度)
- $w$ (宽度)
- $t$ (时间,即视频的第几帧)
早期的多模态模型 (如 Qwen2-VL) 使用 MRoPE (Multimodal RoPE),它简单地把特征维度“分块”,比如:
- 高频特征 $\leftarrow$ [所有时间 $t$ 的信息]
- 中频特征 $\leftarrow$ [所有高度 $h$ 的信息]
- 低频特征 $\leftarrow$ [所有宽度 $w$ 的信息]
这种设计的致命缺陷是,所有“时间”信息都被困在了高频区,导致模型很难理解长距离的时间依赖(比如视频开头和结尾的联系),严重限制了长视频的理解。
Qwen3-VL 的答案:Interleaved-MRoPE (交错式)
Qwen3-VL 采用了更先进的 **Interleaved-MRoPE (I-MRoPE)**。
它不再“分块”,而是像发牌一样,把 $t, h, w$ 三个维度的信息**“交错”地、均匀地“轮询”(Round-Robin)分配到所有**的频率通道中(高、中、低频)。
这意味着,无论是 $t, h, $ 还是 $w$,都能访问到完整的频率频谱。
这种“全频率覆盖”的设计,使得 Qwen3-VL 在处理长视频和复杂空间关系时,能力远超前代。
我输入的是静态图片,哪来的时间 $t$?
答案是:Qwen3-VL 的架构是为更复杂的“视频”任务而设计的。
- 当我输入视频时: 它在 3D 模式 ($t, h, w$) 下全速运行。
- 当我输入图片时: 它只是在 2D 模式 ($h, w$) 下运行,这可以被看作是 $t=1$ 的一种特例。
sping速通
一、 Java 基础:从 Go/Python 到 JVM
1. 语言范式的根本区别
| 特性 | C++/Python/Go 的习惯 | Java 的要求 | 关键点 |
|---|---|---|---|
| 代码结构 | 允许全局函数、模块级函数。 | 所有的可执行代码(方法/逻辑)必须封装在一个 class (类) 或 interface (接口) 中。 | Java 是“纯血”的面向对象语言。你不能写一个脱离类的函数。 |
| 数据类型 | Python (动态),Go (静态但有类型推断)。 | 强类型、静态类型。所有变量必须显式声明类型,一旦声明不能更改。 | 避免 Go 语言中省略类型声明的习惯。 |
| 内存管理 | Go/Python 自动垃圾回收。 | **自动垃圾回收 (GC)**。无指针运算,内存错误率低。 | 与 Go/Python 相似,无需手动管理内存。 |
| 执行机制 | 编译成机器码 (Go/C++) 或解释执行 (Python)。 | 编译成 **字节码 (.class)**,然后在 JVM (Java 虚拟机) 上运行。 | 实现“一次编写,到处运行”。 |
2. JDK 与版本生态
- **Java 版本 (Specification) $\approx$ JDK 版本 (Implementation)**:Java SE 定义了语言特性和 API 规范。JDK (Java Development Kit) 是实现这些规范的工具包。
- 多供应商实现 (OpenJDK): Java 规范由 JCP (Java Community Process) 维护。市面上的主流 JDK,如 Amazon Corretto、Eclipse Temurin、Oracle JDK 等,均基于开源的 OpenJDK 并通过兼容性测试 (TCK)。
二、构建工具对比:Gradle 的现代优势
在 Java 世界中,构建工具负责依赖管理、编译、测试和打包。
| 特性 | Maven (传统) | Gradle (现代) | 优势点 |
|---|---|---|---|
| 配置文件 | pom.xml (XML) | build.gradle (Groovy/Kotlin DSL) | 可读性高,支持编程逻辑。 |
| 配置风格 | 纯声明式 | 编程式与声明式结合 | 极高的灵活性,可定义复杂的自定义任务。 |
| 构建速度 | 每次执行全量构建 | 增量构建、构建缓存 (Cache) | 对于大型和多模块项目,速度明显更快。 |
结论: 对于 Spring Boot 新项目,Gradle 以其灵活性和性能优势,是更推荐的选择。
三、 Spring Boot 核心:依赖注入 (DI) 的魔法
Spring Boot 的设计哲学是 “约定优于配置”,其核心是 **依赖注入 (DI)**。
1. 依赖注入 (DI) 与 IoC 容器
| 机制 | 描述 | 与传统开发的区别 |
|---|---|---|
| 控制反转 (IoC) | 将对象的创建、管理和生命周期的控制权交给 Spring 容器。 | 你不再使用 new MyService() 手动创建对象。 |
| 依赖注入 (DI) | 应用程序所需的依赖(对象)由 Spring 容器自动注入到目标对象中。 | 你只需声明你需要什么 (接口),Spring 负责找到并提供具体的实现。 |
2. 核心注解速查
| 注解 | 作用范围 | 功能描述 |
|---|---|---|
@SpringBootApplication | 主启动类 | 整合配置、自动配置和组件扫描。 |
@Autowired | 构造函数/字段 | 标记 Spring 容器应在此处自动注入依赖对象。 |
@RestController | 类 | 标记为 Web 控制器,方法的返回值自动序列化为 JSON。 |
@Service | 类 | 标记为业务逻辑组件 (Service Layer)。 |
@Repository | 类 | 标记为数据访问组件 (DAO Layer)。 |
四、 Spring Boot 实战:分层与持久化 (JPA)
现代 Spring Boot 应用遵循经典的分层架构,DI 机制将它们解耦。
| 层级 | 技术/注解 | 职责 | 核心原理 |
|---|---|---|---|
| Controller (控制层) | @RestController, @RequestBody, @GetMapping | 接收 HTTP 请求,处理路由,调用 Service,序列化/反序列化 JSON。 | 利用 Jackson 库自动完成 Java 对象与 JSON 格式的转换。 |
| Service (业务层) | @Service | 封装核心业务逻辑和事务管理。 | 依赖注入 Repository 接口。 |
| Repository (数据层) | @Repository, JpaRepository | 与数据库交互。 | 继承 JpaRepository<Entity, ID> 后,Spring Data JPA 会在运行时自动生成基础的 CRUD (增删改查) 实现。 |
| Entity (数据模型) | @Entity, @Id, @GeneratedValue | 定义与数据库表对应的 Java 类。 | 通过 JPA/Hibernate 实现 ORM (对象关系映射)。 |
五、 配置管理与并发模型
1. 现代化配置:YAML 与 Profiles
- YAML (Yet Another Markup Language): 使用
.yml文件替代.properties,利用缩进实现清晰的层次结构,例如:1
2
3spring:
datasource:
url: # ... - Profiles (环境配置): 通过创建
application-{profile}.yml文件来隔离不同环境(dev/test/prod)的配置。 - 激活方式: 启动时使用命令行参数激活特定环境:
--spring.profiles.active=prod
2. 并发模型:Spring MVC vs. WebFlux
| 模型 | Spring MVC (默认) | Spring WebFlux (响应式) | 建议 |
|---|---|---|---|
| 底层架构 | Servlet API, Thread-per-Request (每个请求一个 Java 线程等待) | 非阻塞 I/O,基于 Reactor 库 (类似 Event Loop)。 | 针对 I/O 密集型/高并发 场景,性能更优。 |
| 适用性 | 易于理解,CPU 密集型或传统应用。 | 高吞吐量微服务,类似 Go 的 Goroutine 优势。 | 随着 Java 虚拟线程 (Virtual Threads) 的引入,Java 的并发能力正在发生革命性变化。 |
六、开发环境 (IDE) 推荐
对于 Java 和 Spring Boot 开发,推荐:
- IntelliJ IDEA Community Edition (社区版): 免费且功能强大,提供对 Spring Boot 和 Gradle 最完善、最智能的集成支持,能极大地提高你的开发效率。
claude code
claude-code命令行
1 | npm install -g @anthropic-ai/claude-code --registry=https://registry.npmmirror.com |
通过环境变量修改成kimi的模型1
2
3
4export ANTHROPIC_BASE_URL=https://api.moonshot.cn/anthropic
export ANTHROPIC_AUTH_TOKEN=${YOUR_MOONSHOT_API_KEY}
export ANTHROPIC_MODEL=kimi-k2-turbo-preview
export ANTHROPIC_SMALL_FAST_MODEL=kimi-k2-turbo-preview
或者在claude配置文件中添加环境变量~/.claude/settings.json1
2
3
4
5
6
7
8{
"env": {
"ANTHROPIC_BASE_URL": "https://www.sophnet.com/api/open-apis/7TxazXiOf8xHVzgbxY2o6w/anthropic",
"ANTHROPIC_AUTH_TOKEN": "${YOUR_API_KEY}",
"ANTHROPIC_MODEL": "Kimi-K2-0905",
"ANTHROPIC_SMALL_FAST_MODEL": "Kimi-K2-0905"
}
}
添加mcp,mcp-chrome-bridge确实好用,就是费token1
claude mcp add --transport http mcp-chrome-bridge http://127.0.0.1:12306/mcp
claude-code的vscode插件
应用市场安装先安装一个
在设置中搜索Claude Code: Environment Variables,编辑setting.json1
2
3
4
5
6
7
8
9{
...
"claude-code.environmentVariables": [
{ "name": "ANTHROPIC_BASE_URL", "value": "https://www.sophnet.com/api/open-apis/7TxazXiOf8xHVzgbxY2o6w/anthropic" },
{ "name": "ANTHROPIC_AUTH_TOKEN", "value": "${YOUR_API_KEY}" },
{ "name": "ANTHROPIC_MODEL", "value": "Kimi-K2-0905" },
{ "name": "ANTHROPIC_SMALL_FAST_MODEL", "value": "Kimi-K2-0905" }
]
}
vscode的ai插件真多啊,有官方copilot,有早期的cline,claude code也有了
AIGC归纳
失业的第一天,把现有的关于AIGC的乱七八糟的东西归纳一下
AI大善人们
GPU
腾讯cloud studio
https://cloudstudio.net/my-app
我主要用的是这个平台,每天签到有2核时,大概A10可以用40分钟。有256g的存储,放一些图片和模型文件也够用。有一些现成的comfyUI的应用,还比较好用。
但感觉像没啥人维护了,文档不太好,怎么自己创建应用,在哪里写配置文件没找到。

腾讯cnb
https://cnb.cool/?type=activities
应该和上面用法差不多,只是我没怎么用。
谷歌colab
https://colab.research.google.com
免费用户可以用T4大概4小时,我这两天基本都有,好处是不用搞签到啥的,坏处是每次环境都是新的,重新安装依赖,下一遍模型。我试了index-tts是在这上面部署的。
API
硅基流动
https://cloud.siliconflow.cn/me/models
硅基流动还是挺好的,送我的14块钱一直用不完,模型也比较全,唯独api base
url不好找,https://api.siliconflow.cn/v1
SophNet
https://sophnet.com/\#/model/overview
和硅基流动差不多,开源的模型挺全的,而且api很快,我claude
code用的就是SophNet部署的kimi v2
应用
LibLibAI
https://www.liblib.art/inspiration
主要是来这里学生图提示词的,lora模型比较丰富,还可以训练,但没试过。
index-tts
看了b站的index-tts,类似的能实现声音克隆的还有阿里的CosyVoice,社区的GPT-SoVITS。
index-tts最大特点在于他把音色和情绪解耦了,你可以单独控制声音的情绪。
github.com/index-tts/index-tts.git,可以直接在colab上部署。
做声音有个现成的方式是用minimax.io 可以克隆音色
comfyUI
最近比较流行的生图工具了,支持的模型很多,最早我是想去试用qwen-image的。网页部署唯一比较麻烦的是下载模型,这里附上一些huggingface的命令。1
2huggingface-cli list Kijai/flux-fp8\
huggingface-cli download Kijai/flux-fp8 \--include flux1-dev-fp8.safetensor \--local-dir ./workspace/Comfyui/models/unet
comfyUI也不用自己搭,有很多平台能用,阿里、LibLib、runninghub都有
对做视频比较好用的几个模型
wan2.2-animate,能做吴京视频。
Wan-Animate supports two modes: (1) Animation mode, which generates high-fidelity character animation videos by precisely replicating the facial expressions and body movements from the reference video; (2) Replacement mode, which seamlessly integrates the character into the reference video, replacing the original character while reproducing the scene’s lighting and color style to achieve natural environmental blending.
humo,可以做数字人。
SillyTavern
https://github.com/SillyTavern/SillyTavern
这个就比较偏娱乐了,文字冒险游戏了,最基础的是对话,然后可以加入生图和tts,都是走api的,所以本地只有cpu的机器也可以跑。
角色卡可以自己捏,也可以到网上下,比如类脑上的,大部分是NSFW。
要生图的话是走插件,需要安装这个插件https://github.com/wickedcode01/st-image-auto-generation,安装后就会出现"Image
Auto
Generation”插件,这个插件会要求在每次生成内容后,再生成一段生图的prompt。
左侧我选的是ComfyUI,ComfyUI用的是前面腾讯cloud
studio部署的,也可以api调用。ComfyUI的dag图是这个json文件,我不太会改,只是把模型从sd1.5换到了3.5。
tts我没有配置。
CS336
还是不能忘记学习,https://stanford-cs336.github.io/spring2025/,
https://www.bilibili.com/video/BV1YKhhzBE1M/?vd\_source=d4d45a41db226393d3b605dd30e2ffa8
gemini的gem
Veo Visionary | Text-to-Video Generator

diffusion模型基础
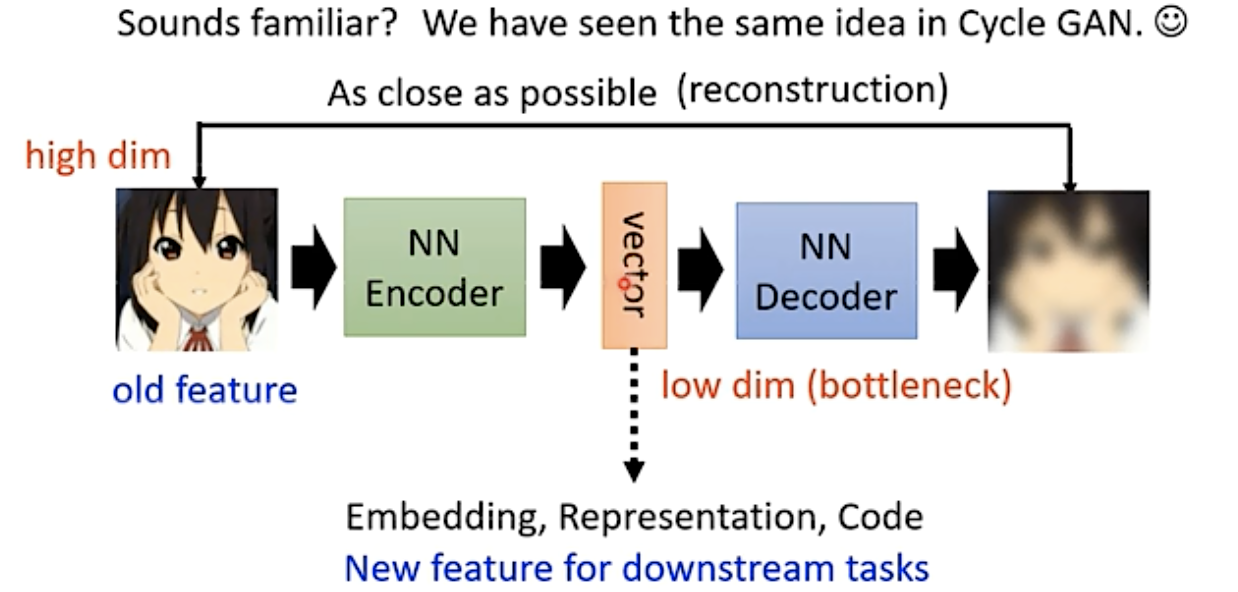
auto encoder
训练目标是:希望输入的图片经过两次转换和原来的图片越接近越好,也被称为“重构-reconstruction”(不需要有标签的数据)
常见的应用:原来的向量维度很高,经过encoder之后输出维度小的向量,再用这个低维度的向量去做后面的任务。
auto encoder严格来说不算生成模型,只是在重构,到VAE才算具备的生成能力。
VAE(变分自编码器)
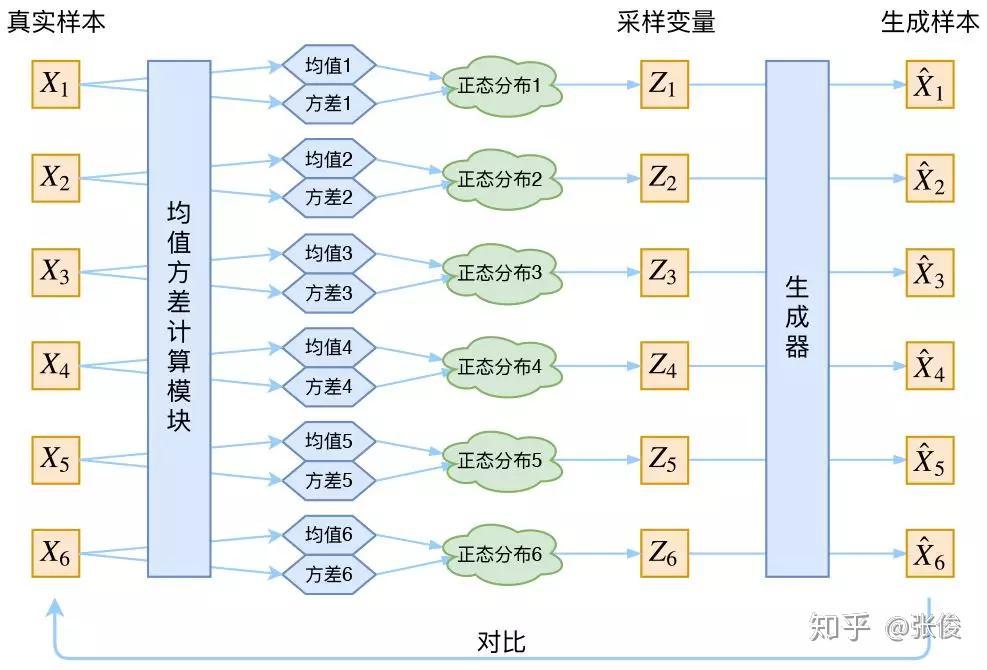
VAE 是一种概率生成模型,通过编码器将输入数据映射到潜空间,再通过解码器从潜空间重构数据。
在VAE中,我们假设$p(Z|X)$后验分布是正态分布,给定一个真实的样本$X_k$,都有专属的分布$p(Z|X_k)$。训练生成器时,采样一个$Z_k$来还原$X_k$。
VAE 的损失函数由两部分组成:
- reconstruction loss(重构损失):衡量重构输入 $\hat{X}$ 与原始输入 $X$ 的相似度,常用均方误差(MSE):
$$
\text{reconstruction loss} = | X - \hat{X} |^2
$$
其中 $\hat{X}$ 是解码器生成的重构结果。
- similarity loss(相似性损失):即 KL 散度,衡量潜在分布 $\mathcal{N}(\mu, \sigma)$ 与标准正态分布 $\mathcal{N}(0, I)$ 的差异,可以当做是一个正则项。
$$
\text{similarity loss} = D_{KL}(\mathcal{N}(\mu, \sigma) | \mathcal{N}(0, I)) \
=\frac{1}{2}(-log\sigma ^2+\mu ^2+\sigma ^ 2 - 1)
$$
VAE的训练过程本质上是重建损失和KL散度损失之间的权衡:重建损失希望编码器学习到区分度大、能精确重建的潜在表示,这可能倾向于让$\mu$分散、$\sigma$变小。KL散度损失则希望所有分布收缩到0和1,防止VAE退化成普通AE,失去生成新样本的能力。
$$
\text{loss} = \text{reconstruction loss} + \text{similarity loss}
$$
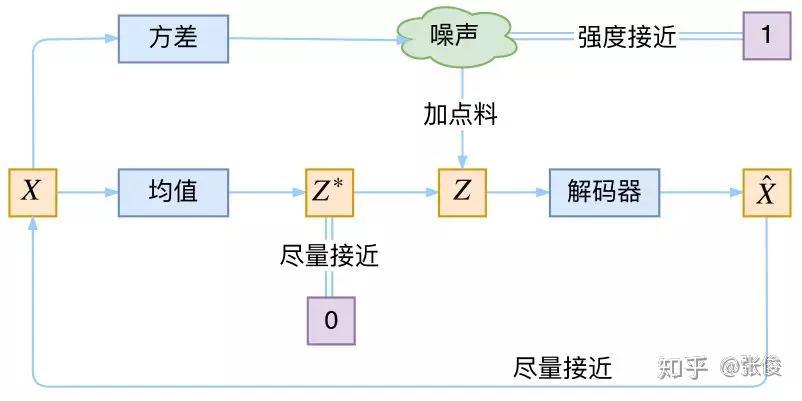
VAE存在一个固有问题,是用L2距离来衡量$\hat{X}$ 与 $X$ 的相似度,L2距离只是近似等于分布距离,会导致图片变得模糊(倾向于生成低频信号,这样L2 loss小)。
GAN(生成对抗网络)
GAN的思路是reconstruction loss不好衡量,我就用个模型来代替,多加了一个discriminator来判断图片是生成的还是真实的。训练过程是generator和discriminator交替进行。
我以前也写过GAN,当时GAN还很火。
$$
\min_G \max_D V(D,G) = E_{x \sim p_{\text{data}}(x)}[\log D(x)] + E_{z \sim p_{z}(z)}[\log(1 - D(G(z)))]
$$
这是生成对抗网络(GAN)的价值函数(Value Function)或目标函数(Objective Function)。
- $G$ 代表生成器(Generator),其目标是最小化这个函数($\min_G$)。
- $D$ 代表判别器(Discriminator),其目标是最大化这个函数($\max_D$)。
- $V(D, G)$ 是判别器 $D$ 和生成器 $G$ 之间的二人极小极大博弈的值。
公式组成部分:
$E_{x \sim p_{\text{data}}(x)}[\log D(x)]$:
- 这是判别器正确判断真实数据 $x$ 为真的期望。
- $p_{\text{data}}(x)$ 是真实数据分布。
- $D(x)$ 是判别器将真实数据 $x$ 判为真的概率。
- 判别器 $D$ 想要最大化这一项,使其接近 $1$($\log(1)=0$)。
$E_{z \sim p_{z}(z)}[\log(1 - D(G(z)))]$:
- 这是判别器正确判断生成数据 $G(z)$ 为假的期望。
- $p_{z}(z)$ 是噪声输入 $z$ 的先验分布。
- $G(z)$ 是生成器 $G$ 生成的假样本。
- $D(G(z))$ 是判别器将假样本 $G(z)$ 判为真的概率。
- 判别器 $D$ 想要最大化这一项,即使 $D(G(z))$ 接近 $0$($\log(1-0)=\log(1)=0$)。
- 生成器 $G$ 想要最小化这一项,即使 $D(G(z))$ 接近 $1$,从而骗过判别器。
Diffusion(扩散模型)
Diffusion 模型是一类基于概率扩散过程的生成模型。其核心思想是将数据逐步加噪声,最终变成纯噪声,然后训练一个模型学会如何一步步去噪,最终还原出原始数据。Diffusion 模型近年来在图像生成等任务上取得了极大成功,代表模型有 DDPM、Stable Diffusion 等。
Diffusion 模型包括两个过程:正向扩散过程(加噪声)和反向去噪过程(生成)。
1. 正向扩散(Forward Process)
正向过程将原始数据 $x_0$ 逐步加入高斯噪声,经过 $T$ 步后变成接近各向同性高斯分布的噪声 $x_T$。每一步的加噪过程如下:
$$
q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t I)
$$
其中 $\beta_t$ 是每一步的噪声强度。
2. 反向去噪(Reverse Process)
反向过程的目标是从纯噪声 $x_T$ 开始,逐步去噪,最终还原出数据 $x_0$。反向过程同样是高斯过程,但均值和方差需要模型学习:
$$
p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))
$$
训练时,通常用一个神经网络(如 U-Net)预测噪声或数据的均值。
Diffusion 模型的训练
Diffusion 模型的训练目标是让模型学会在每一步准确地去噪。常见的训练方式是让模型预测每一步加到数据上的噪声 $\epsilon$,损失函数为:
$$
L_{simple} = E_{x_0, \epsilon, t} \left[ | \epsilon - \epsilon_\theta(x_t, t) |^2 \right]
$$
其中 $x_t$ 是在 $t$ 时刻加噪后的数据,$\epsilon$ 是实际加的噪声,$\epsilon_\theta$ 是模型预测的噪声。
训练流程如下:
- 从数据集中采样一张图片 $x_0$。
- 随机采样一个时间步 $t$。
- 按照正向扩散公式加噪,得到 $x_t$。
- 用神经网络输入 $x_t$ 和 $t$,预测噪声 $\epsilon_\theta$。
- 计算损失并反向传播,更新模型参数。
Diffusion 模型的推理(采样)
推理阶段,从高斯噪声 $x_T$ 开始,利用训练好的模型逐步去噪,最终生成一张图片。每一步的采样过程如下:
- 初始化 $x_T \sim \mathcal{N}(0, I)$。
- 对 $t = T, T-1, …, 1$:
- 用模型预测当前噪声 $\epsilon_\theta(x_t, t)$。
- 计算 $x_{t-1}$ 的均值和方差。
- 从高斯分布采样 $x_{t-1}$。
- 最终得到 $x_0$,即生成的图片。
推理过程可以理解为“逆过程”,逐步将噪声还原为清晰的样本。采样步数越多,生成质量越高,但速度越慢。近年来也有很多加速采样的改进方法。
BLEU和GLUE
攒了好多年的问题了,该了结一下了。
BLEU 机器翻译指标
transormer那篇论文里提到了BLEU指标,但一直不知道这个指标是啥。
BLEU(Bilingual Evaluation Understudy),通过比较机器翻译的结果与参考译文之间的相似度来衡量翻译质量。
$$
BLEU=BP*exp(\sum_{n=1}^N\frac{1}{N}logP_n)
$$
N取4,即最多4-gram
BP(Brevity Penalty)是长度惩罚因子,$l_c$代表表示机器翻译译文的长度,$l_s$表示参考答案的有效长度,避免机器翻译太短,hack了$P_n$指标,本质上还是$P_n$只考虑了准确率,没考虑召回率。
$$
BP = \begin{cases}
1 & l_c \ge l_s \
exp(1-\frac{l_c}{l_s}) & l_c < l_s
\end{cases}
$$$P_n$,n-gram,比较译文和参考译文之间n组词的相似的占比。
比较详细的可以参考这里。
GLUE
GLUE(General Language Understanding Evaluation)是一个综合性的GLU(自然语言理解)评估基准,通过9个英语任务测试模型的通用能力,取平均值。
单句分类任务
- CoLA:纽约大学发布的有关语法的数据集,该任务主要是对一个给定句子,判定其是否语法正确,因此CoLA属于单个句子的文本二分类任务
- SST(情感分析):是斯坦福大学发布的一个情感分析数据集,主要针对电影评论来做情感分类,因此SST属于单个句子的文本分类任务(SST-2是二分类,SST-5是五分类,SST-5的情感极性区分的更细致)
相似性任务
- MRPC/QQP(句子对语义等价判断):判断两个给定句子,是否具有相同的语义,属于句子对的文本二分类任务
- STS-B(句子相似度评分):用1到5的分数来表征两个句子的语义相似性,本质上是一个回归问题,但依然可以用分类的方法做,因此可以归类为句子对的文本五分类任务
推理任务
- MNLI/QNLI/RTE/WNLI(文本蕴含与推理)
也是比较老的指标了,BERT、T5那个时代的。