看过的论文汇总
论文常看常忘,还是把看过的先记下来,再补充总结
NET
pvanet
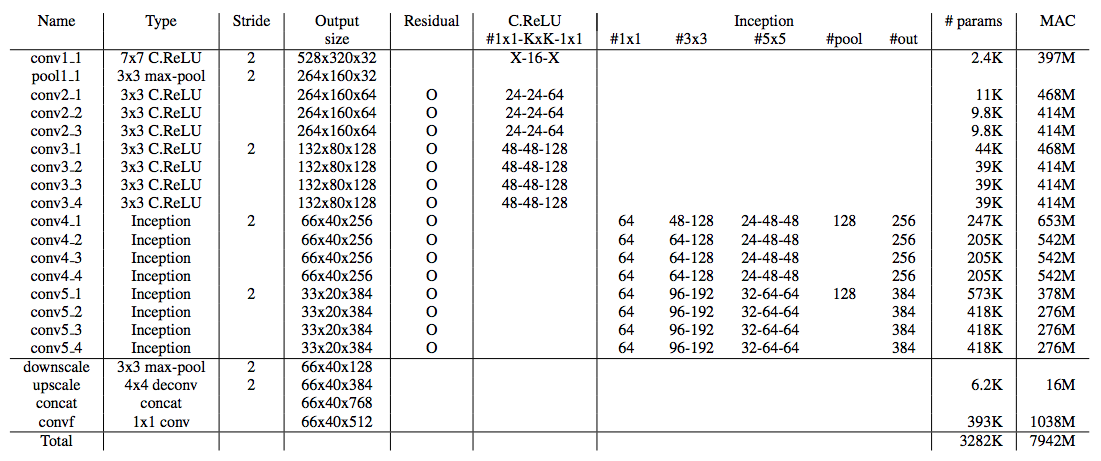
- pvanet是为了实时目标识别提出来的网络,用来提取特征的,用了很多方法来减小计算量,看起来像个大杂烩
- C.ReLU,由于观察到浅层的网络卷基层总是存在互补层,所以直接把卷积取反再concatenate,可以减少一半的计算量
- Inception,使用了inception unit,用两个3*3的卷集合替代了5*5的卷积,也是为了减小计算量
- HypteNet多层融合,融合哪两层是比较讲究的,选择不好的话,会白白增加计算量。这里作者使用了最后输出层2倍和4倍多layer进行融合,以2倍的layer为标准,分别pooling和差值upscale。
- ResNet,再inception unit里也用了残差网络。
- 整个网络结构如下表
- pvanet里还提到了一种学习策略,动态调整学习率,如果一定的迭代次数内,loss下降小于阈值,就说明是on plateau,这时候就降低学习率。在github上有人实现,只不过没有被merge进来。
mobilenet
shufflenet
- mobile和shuffle可以看以前写的这篇
densenet
- 每一层都有来自前面所有层的输入,L个层,就是$\frac{L*(L+1)}{2}$个连接。
- Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision.
- resNet中,l层的输出是l-1的非线性加l-1
$$x_l = H_l(x_{l-1}) + x_{l-1}$$
- denseNet中,是直接做的concatenate
$$x_l = H_l([x_0, x_1, …, x_{l-1}])$$
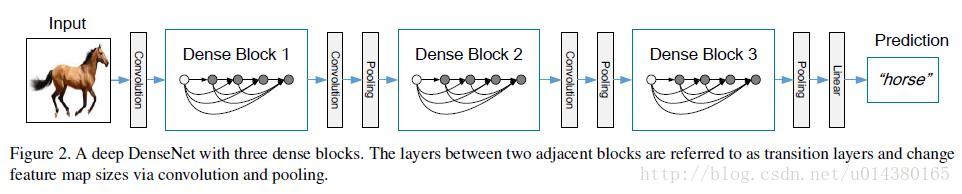
- denseNet中包含三个dense block,如下图所示(盗图自这里)
- 整个网络的结构图如下
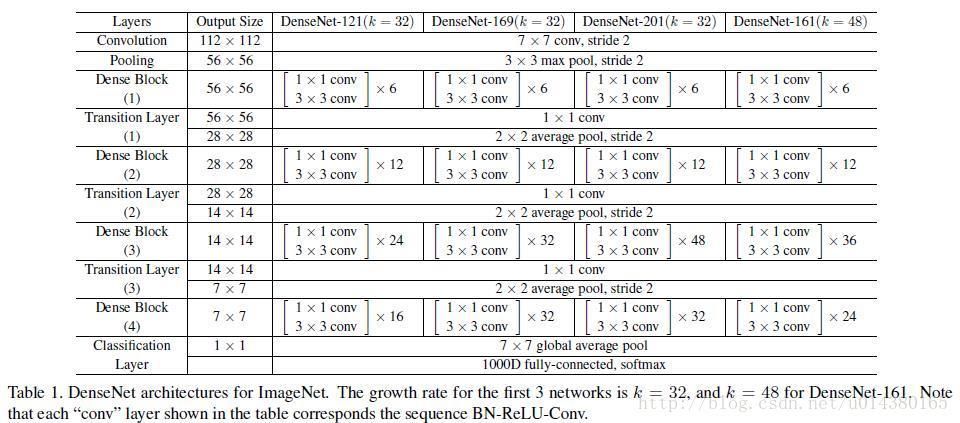
由于denseNet是concatenate,所以到最后一层的时候,channel会异常地大,所以每个3*3卷积前,会有个1*1的bottle neck层,减小channel数量
dense block之间还有transition层,也是用1*1的卷积减小channel数
Attention 和 CTC
Attention is all you need
CTC
text localization
EAST
- 用于文本检测,输出可以是四边形或rotated box
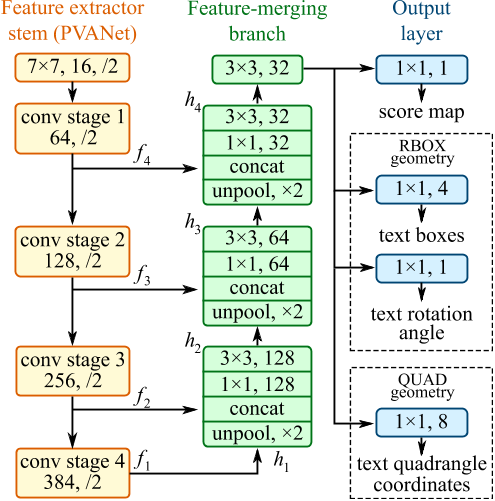
- 最左边用的是PVANet,也可以换成其他ResNet什么的
- 然后中间是特征融合,这里作者借鉴了U-net的做法,用到了unpool,原因是文字有大有小,需要有不同的感受野
- 最后是输出层,包括score map和位置信息,输出的size是原图的1/4大小
- score对应的ground truth: 是将原始的bounding box按照短边长度r向内收缩了0.3r的距离。不懂为什么要这么做
- 针对bounding box内部的每个点,计算他们到上下左右四个边的距离,并且计算角度。针对bounding box外部的点,ground truth置为0
- loss包含两个部分,score map的loss和位置坐标的loss
- score的loss使用的是balanced cross entropy,可以配合正负样本不均衡的情况
$$ L_s = -\beta Y^* log(\hat{Y}) - (1-\beta)(1-Y^*)log(1-\hat{Y})$$
$$ \beta = 1 - \frac{\sum_{y^* \in Y^*} y^*}{|Y^*|}$$
- 位置坐标的loss我只看了rotated box的,又可以分成两个部分,iou的loss和角度的loss,角度的loss前面会乘个系数,10或者20,是个超参数
InceptText from Alibaba, IJCAI2018
text recognition
FAN
Edit Probability
OCR end2end
an end to end textspotter with explicit aligment and attention, ICCV2018
Textbox++
OCR 综述
Text Detection and Recognition in Imagery: A Survey
Character Segmentation
A Gradient Vector Flow-Based Method for Video Character Segmentation, ICDAR201z1
GAN and Draw
- GAN可以看GAN总结
- draw
General CV
YOLO
SSD
Faster rcnn
mask rcnn
FCN
- FCN里用到了三个技术,全卷积、上采样和跳层链接
- 全卷积:一般的CNN最后会有全连接层,把二维的图像压缩成以为的向量,FCN把全连接换成了卷积,实际上计算上是等价的。
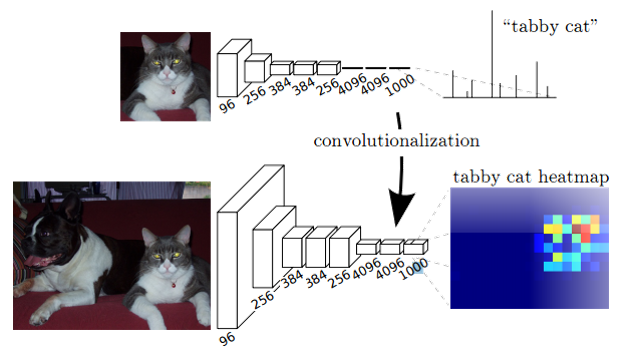
- 上采样:或者叫反卷积、转置卷积(Caffe和Kera里叫Deconvolution,tensorflow里叫conv_transpose)。
- 跳层连接:将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以用不同池化层的结果进行上采样之后来优化输出。
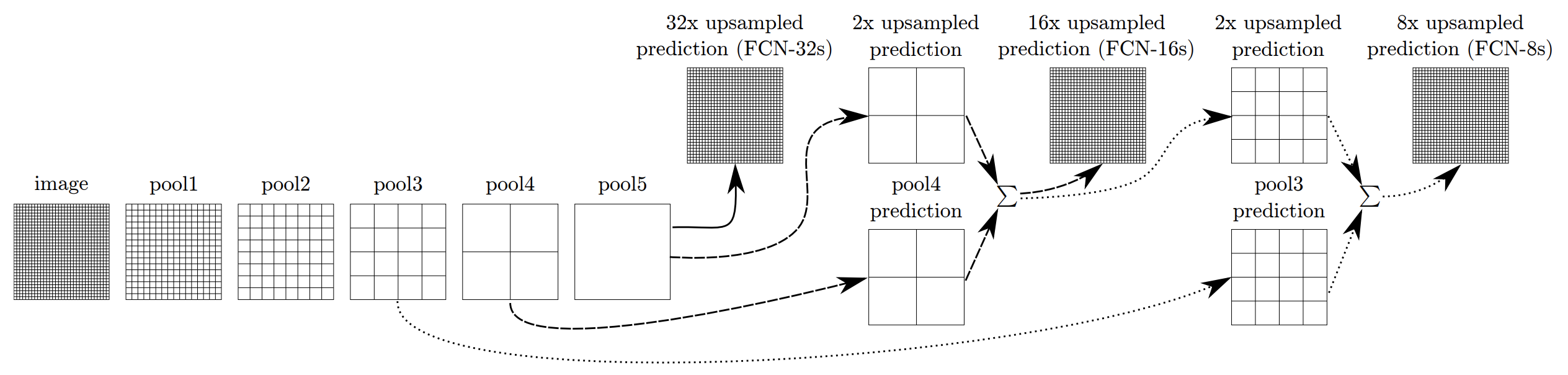
- 原文感觉不好看,主要参考了这里
deeplab
- deeplab可以看以前写的这篇
Visualization
Understanding neural Networks Through Deep Visualization