GAN总结
GAN原理
- GAN的终极目的,其实是用$P_G(x)$拟合真实的$P_{data}(x)$,最直接的想法是用MLE来做,MLE实际上和最小化KL距离是等同的,证明见下张图

机器之心的这篇,基本就是照着李宏毅对课件写的,可以主要看一下为什么说判别器可以衡量两个分布之间的JS散度
GAN的过程

- Goodfellow说上面这种形式的判别器$min \ log(1 − D(G(z)))$不好收敛,就搞成了$max \ log(D(G(z)))$,据李宏毅说,这个修改没啥用,只是Goodfellow偷懒而已。但论文里还是挺有道理的。
In practice, equation 1 may not provide sufficient gradient for G to learn well. Early in learning,
when G is poor, D can reject samples with high confidence because they are clearly different from
the training data. In this case, log(1 − D(G(z))) saturates. Rather than training G to minimize
log(1 − D(G(z))) we can train G to maximize log D(G(z)). This objective function results in the
same fixed point of the dynamics of G and D

conditional GAN
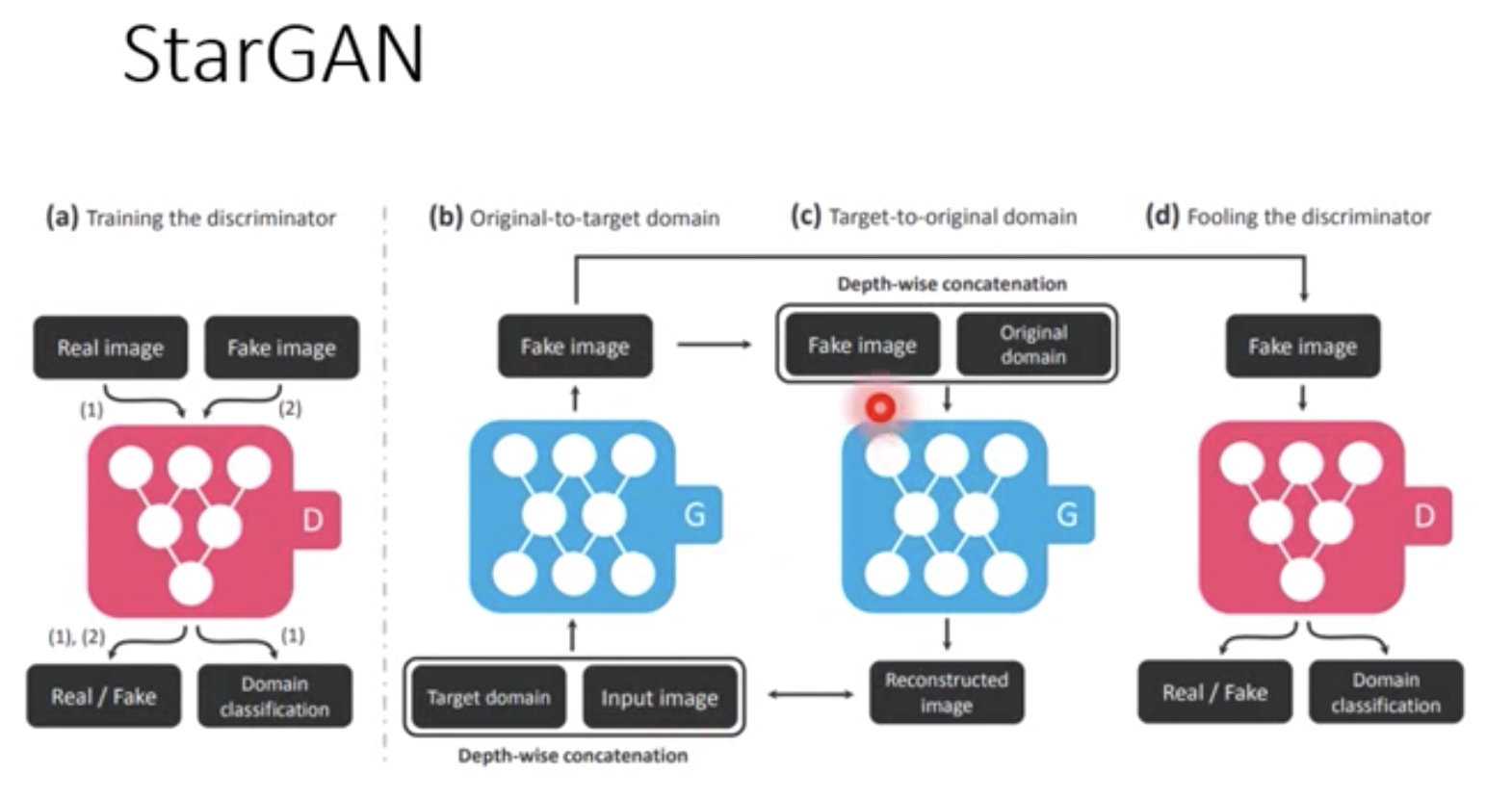
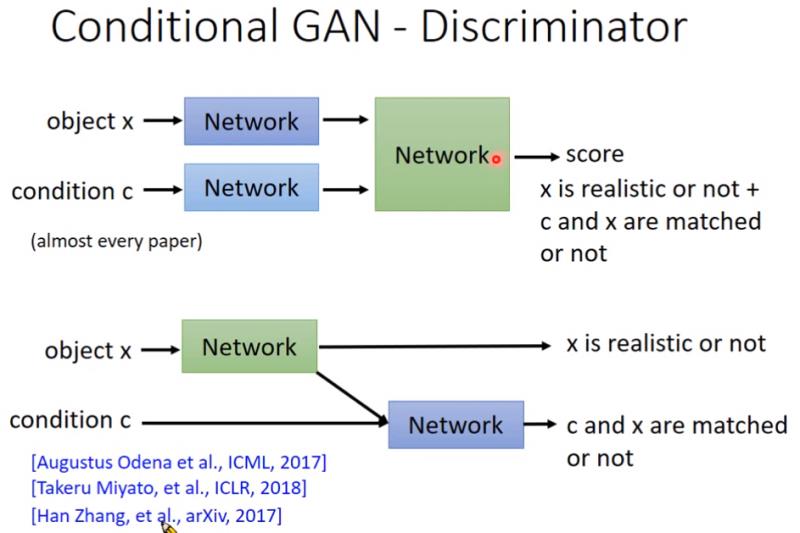
- 除了图片是否真实外,判别器还要区分生成的图片类别对不对

- 这种结构的判别器会好一点
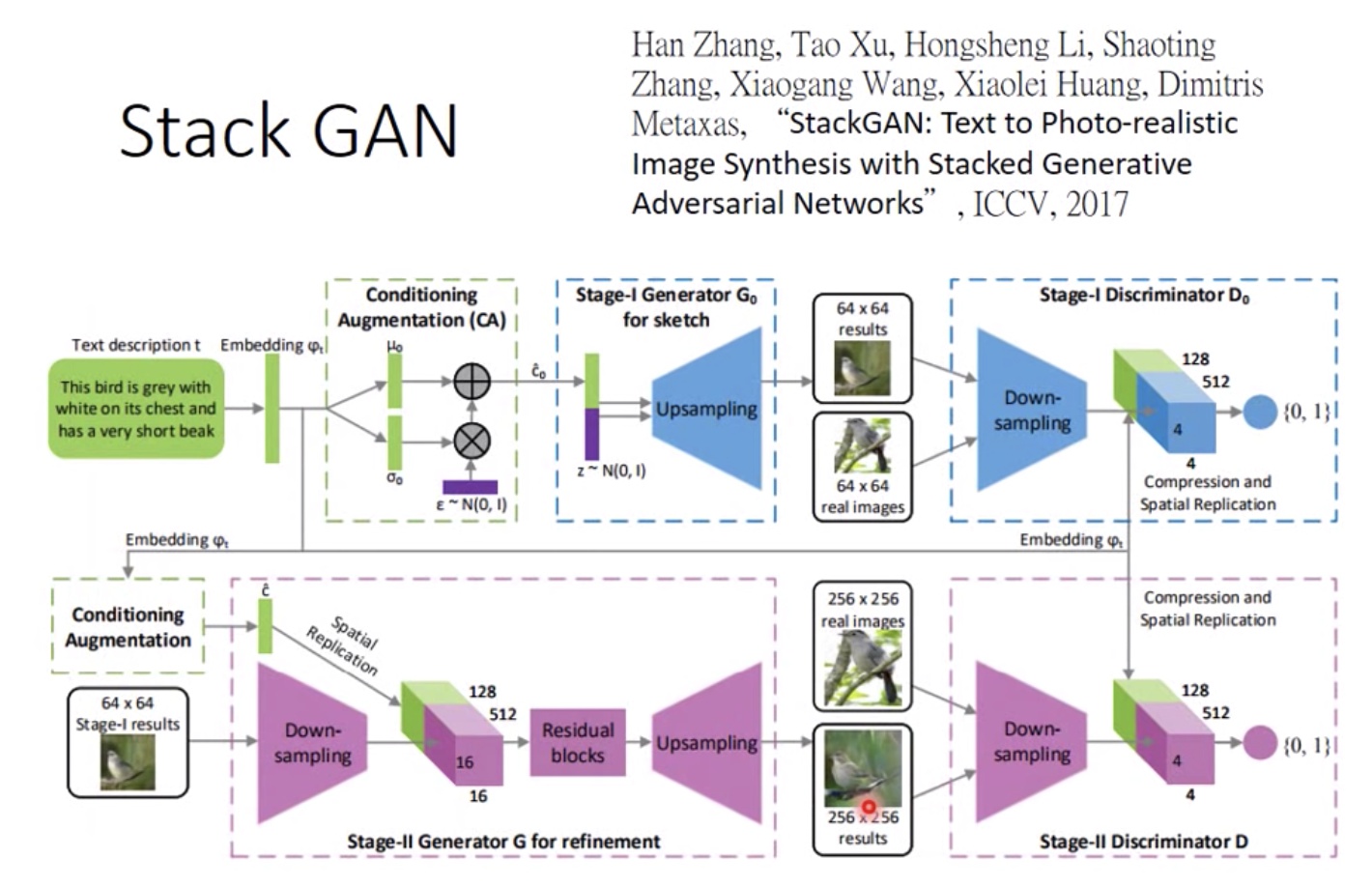
- stack_GAN,GAN直接生成大图的话会比较模糊,所以用两阶段的方法
- 语音增强和image2image也都可以看作是cGAN
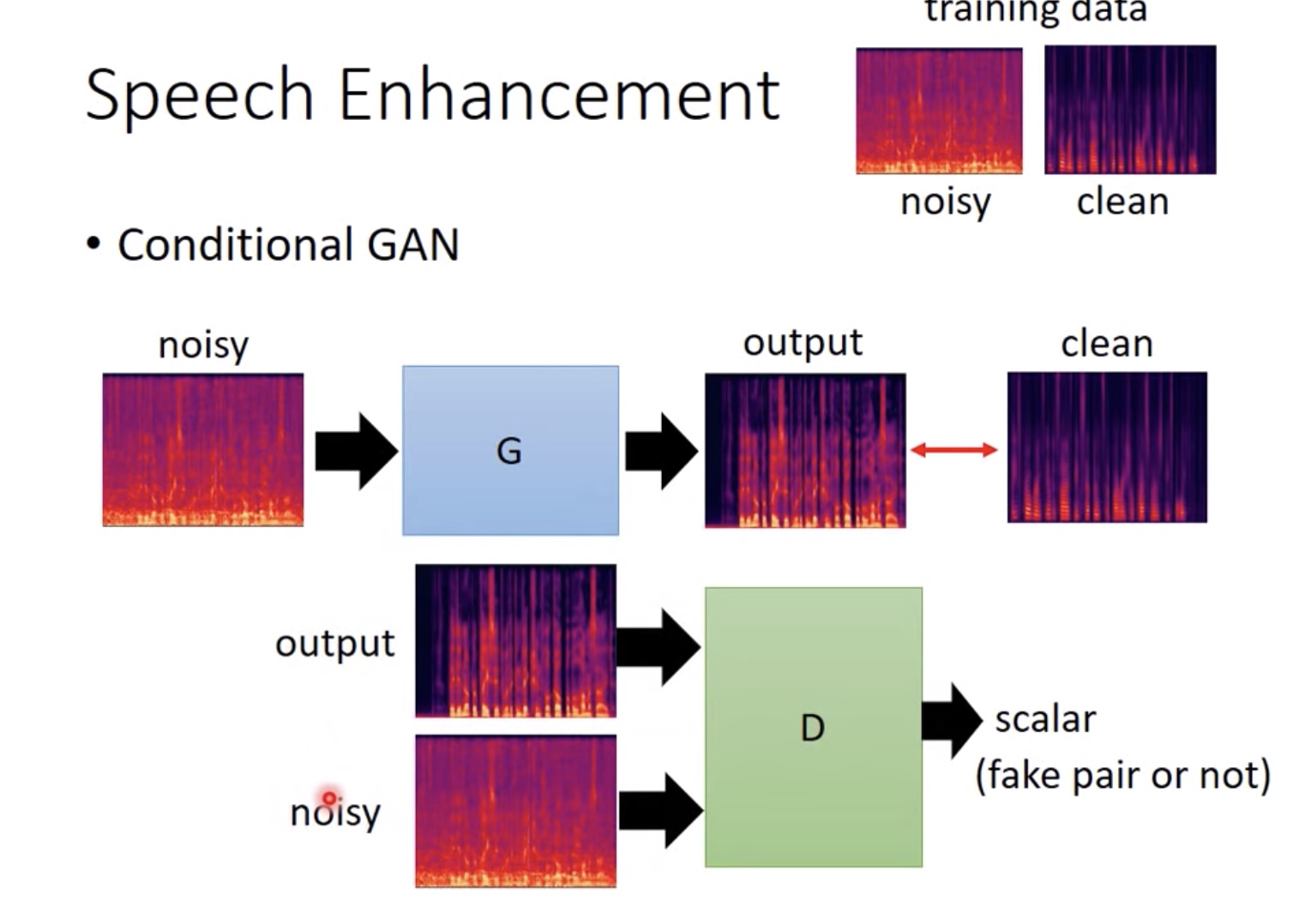
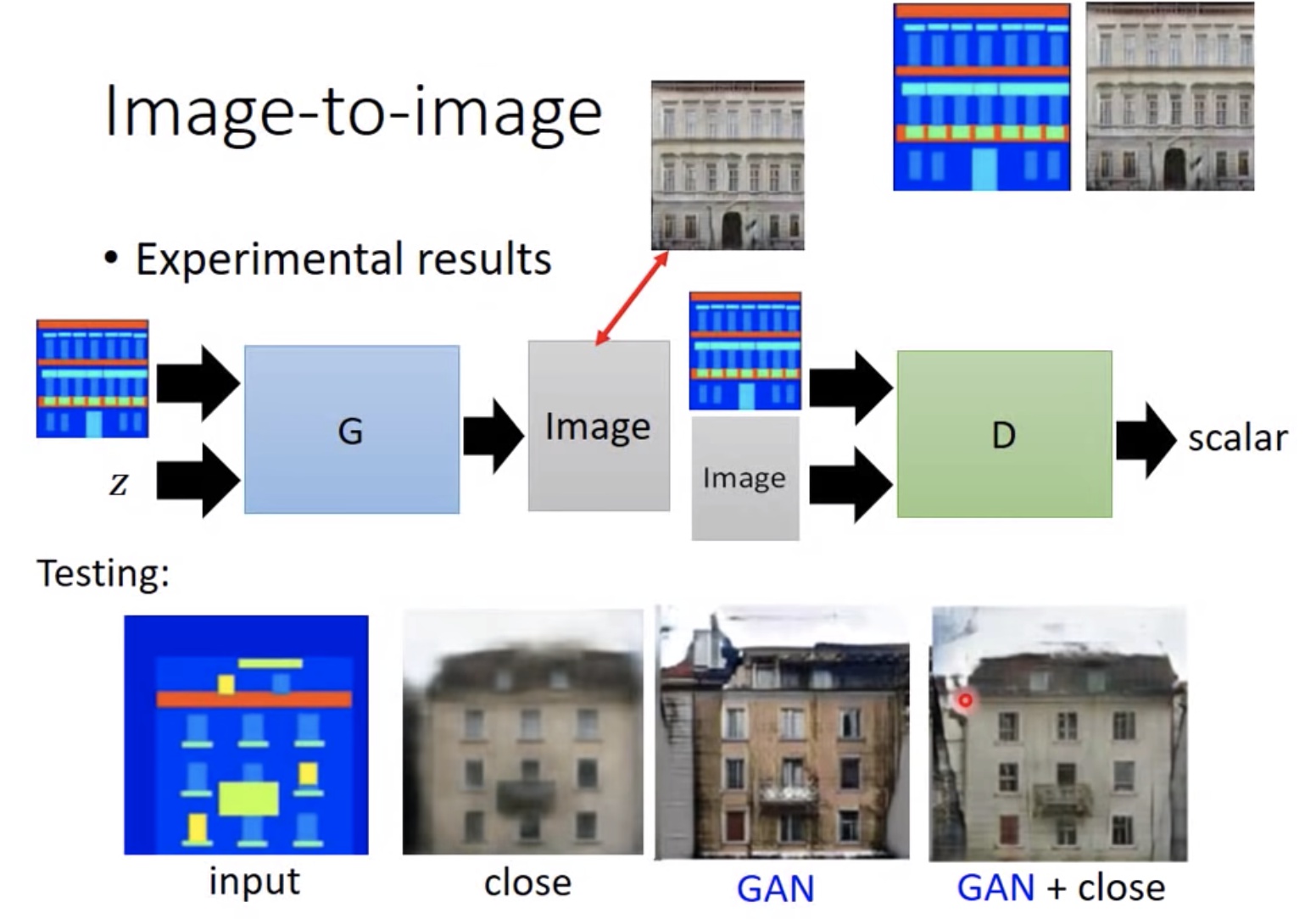
unsupervised conditional GAN
- 问题:没有监督之后,generator可能会生成很真实,但不满足条件的图片
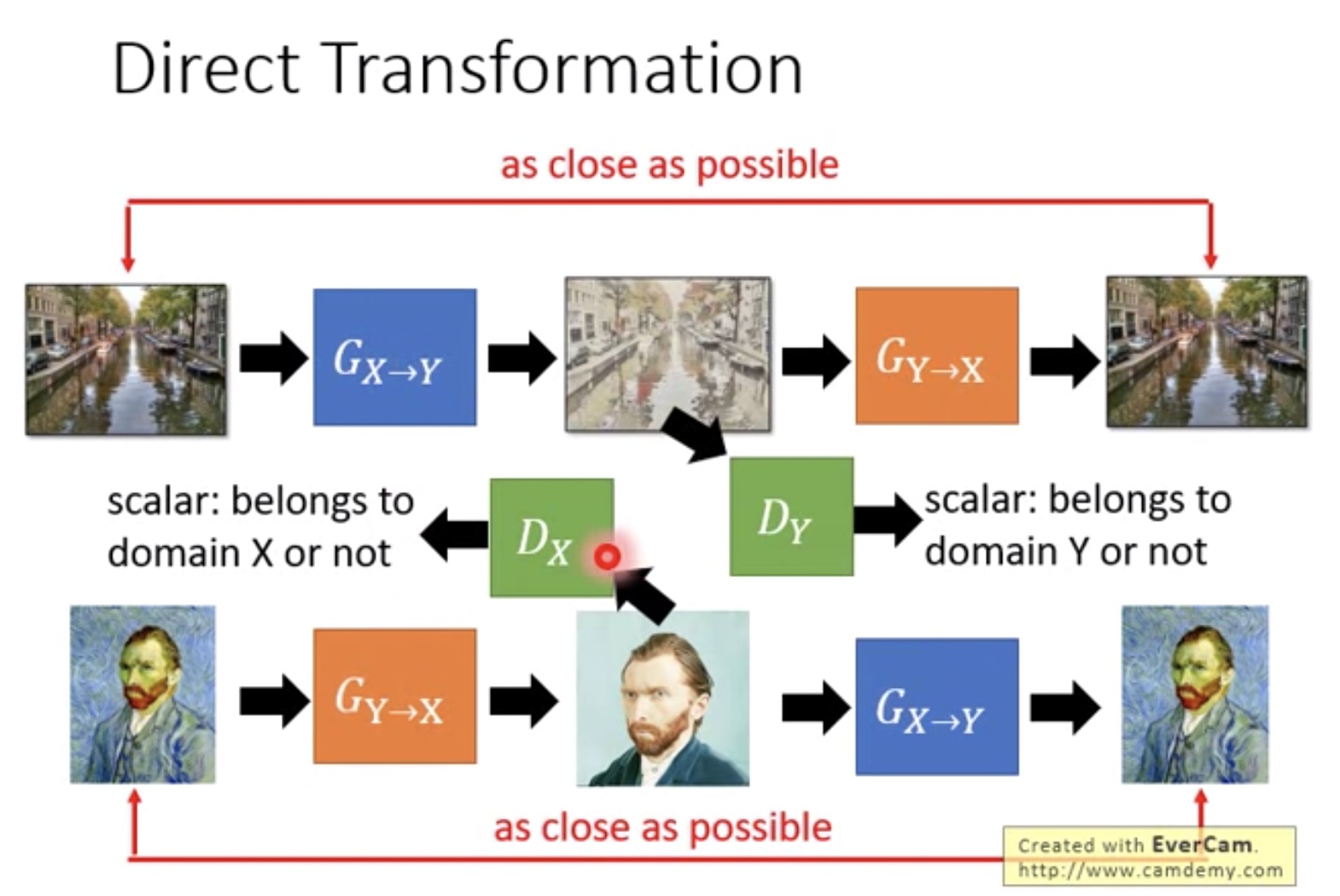
- 办法1,直接忽略这个问题,因为如果generator不是太深的话,生成图片和输入图片还是相关的
- 还有一些加入consistency
![]()
![]()