记一点推荐的基础知识
推荐水哥的这个系列
我这记一点里面需要注意的知识
AUC/GAUC
阿里提出了一个新的评价指标 Group AUC,是用户维度加权的auc
$$
GAUC = \frac{\sum w_u AUC_u}{\sum w_u}
$$
这里的w代表权重,可以是曝光数、点击数,更倾向于高活用户。
AUC这篇写挺好的
auc曲线横坐标是$FPR=\frac{FP}{FP+TN}$,假阳率,预测为阴性里有多少是阳的,越小越好
纵坐标是$FPR=\frac{TP}{TP+FN}$,真阳率,召回率,预测为阳性的里面有多少是真阳性,越大越好
AUC可以看做随机从正负样本中选取一对正负样本,其中正样本的得分大于负样本的概率
可以使用sql来计算AUC
假设我们将测试集的正负样本按照模型预测得分从小到大排序,对于第j
个正样本,假设它的排序为 rj, 那么说明排在这个正样本前面的总样本有 rj−1
个,其中正样本有 j−1 个(因为这个正样本在所有的正样本里面排第j), 所以排在第j个正样本前面(得分比它小)的负样本个数为 rj−j个。也就是说,对于第j个正样本来说,其得分比随机取的一个负样本大(排序比它靠后)的概率是 (rj−j)/N−,其中N−是总的负样本数目。所以,平均下来,随机取的正样本得分比负样本大的概率为$$
AUC = \frac{1}{N_+} \sum_{j=1}^{N_+}(r_j - j)/N_- \
= \frac{\sum_{j=1}^{N_+}r_j - N_+(N_+ + 1)/2}{N_+N_-}
$$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15select
(ry - 0.5*n1*(n1+1))/n0/n1 as auc
from(
select
sum(if(y=0, 1, 0)) as n0,
sum(if(y=1, 1, 0)) as n1,
sum(if(y=1, r, 0)) as ry
from(
select y, row_number() over(order by score asc) as r
from(
select y, score
from some.table
)A
)B
)C
NDGC
Normalized Discounted Cumulative Gain,是衡量排序效果的指标。
还是这位😡老哥说得清楚
理清楚顺序,GC->DGC->NDGC
$$
DCG@K = \sum_{k=1}^{K} \frac{rel_k}{\log_2(k + 1)}
$$
$$
IDCG@K = \sum_{k=1}^{|REL|} \frac{rel_k}{\log_2(k + 1)} = max DGC@K
$$
$$
NDCG@K = \frac{DCG@K}{IDCG_K}
$$
reg-AUG
我理解是没办法画ROC曲线出来,还是沿用了AUC的物理含义,任选两个样本,pred和label单调的概率。
可以用逆序对来计算(mergesort)。
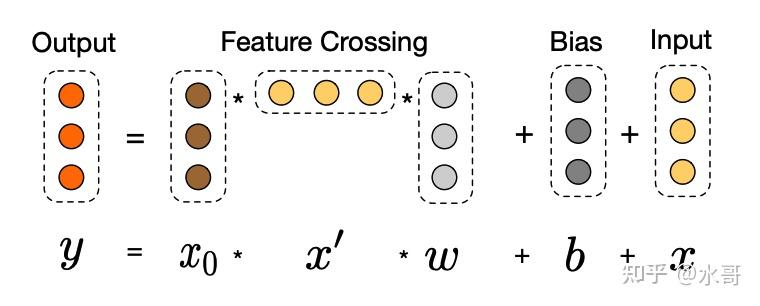
DCN DCNv2
dcn,不是很经得起推敲,$x_l^TW_l$相当于一个常数了,作用在$x_0$上,没有起到交叉的作用,本质原因还是因为$W_l$只是一个向量。
$$
x_{l+1} = x_0x_l^TW_l+b_l+x_l
$$
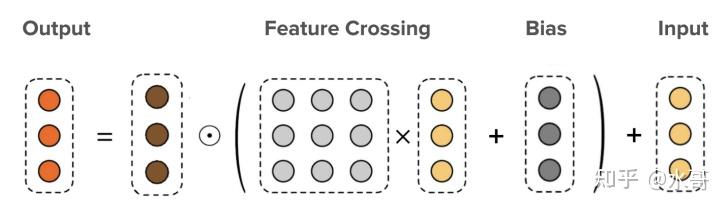
dcn-v2,最大的变化是$W_l$从向量变矩阵了,但因为是bit-wise的交叉,所以参数量比较大,可以做低秩分解。
$$
x_{l+1}=x_0\odot(W_lx_l + b_l)+x_l
=x_0\odot(U_lV_l^Tx_l + b_l)+x_l
$$