GPTs
| 模型 | 发布时间 | 层数 | 头数 | 词向量长度 | 参数量 | 预训练数据量 |
|---|---|---|---|---|---|---|
| GPT-1 | 2018 | 12 | 12 | 768 | 117M | 约 5GB |
| GPT-2 | 2019 | 48 | - | 1600 | 1.5B | 40GB |
| GPT-3 | 2020 | 96 | 96 | 12888 | 175B | 45TB |
| instructGPT | 2022 | 96 | 96 | 12888 | 175B |
GPT1
数据集:BooksCorpus数据集包含7000本没有发布的书籍。选这个数据集的原因有二:1. 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;2. 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
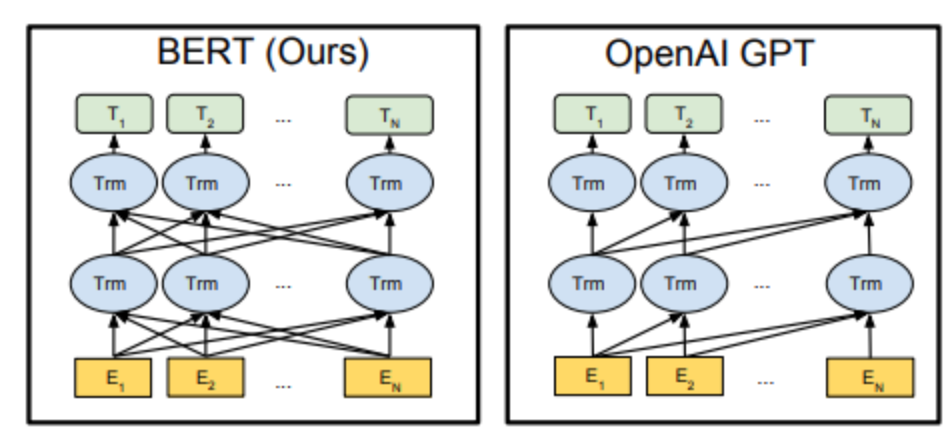
网络结构:12层transformer,每个有12个头,使用BPE编码,编码长度768,位置长度3072也参与训练。
- 单向transformer,使用masked self attention,对于当前词,只能感知到位置靠前词的信息
![1749978474703]()
- pretrain,根据前1024个词,预测下一个词,最大似然函数
- finetune,监督任务和无监督任务一起训练
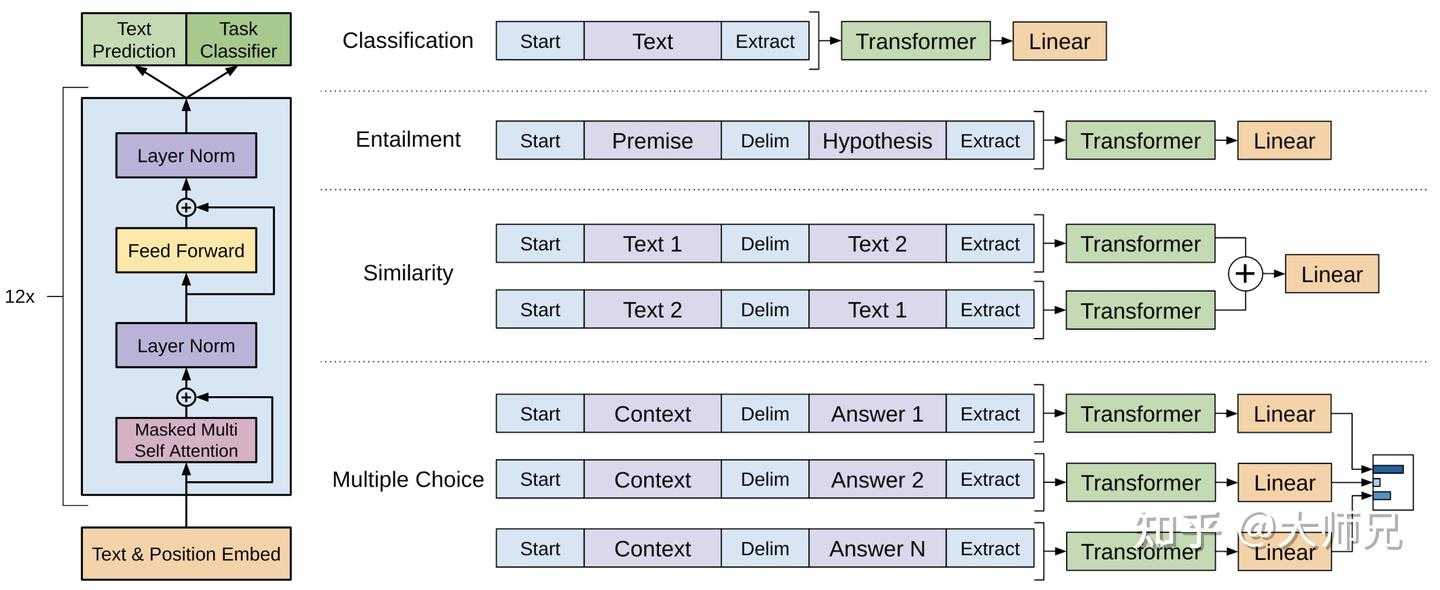
有4个任务
- 分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
- 自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
- 语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推理:将n个选项的问题抽象化为n个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
GPT2
核心思路:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。完全舍弃了finetune,验证zero-shot能力。把单任务的 $P(output | input)$ 改成更具通用性的 $P(output | input,task)$。
数据集:Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
网络结构:48层的transformer,增加了一个LN层。
GPT3
In-context learning,$P(output | input)$ 到 $P(output | input,example)$。
类似于MAML元学习,外循环是无监督的语言模型,内循环是各种情境学习。
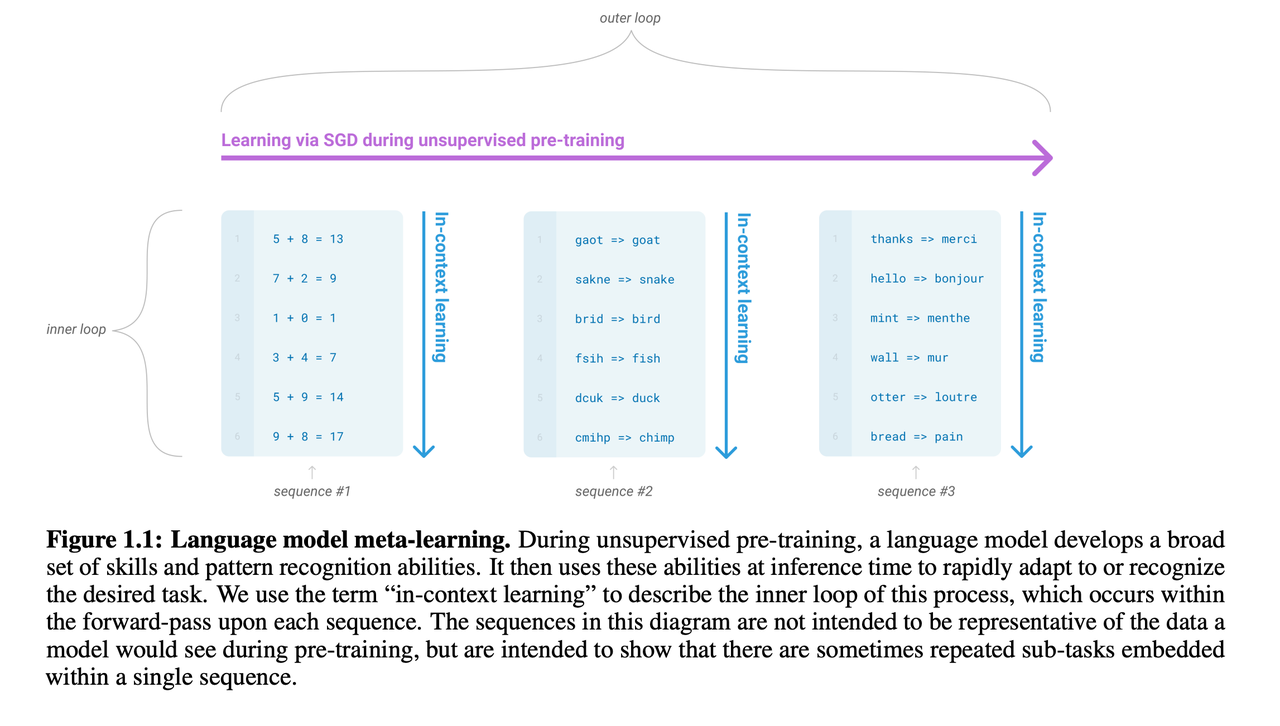
数据集:Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia
网络结构:96层96个头,词向量12888(怎么是个奇怪的数),GPT系列从1到3,通通采用的是transformer架构,模型结构并没有创新性的设计。
instruct GPT
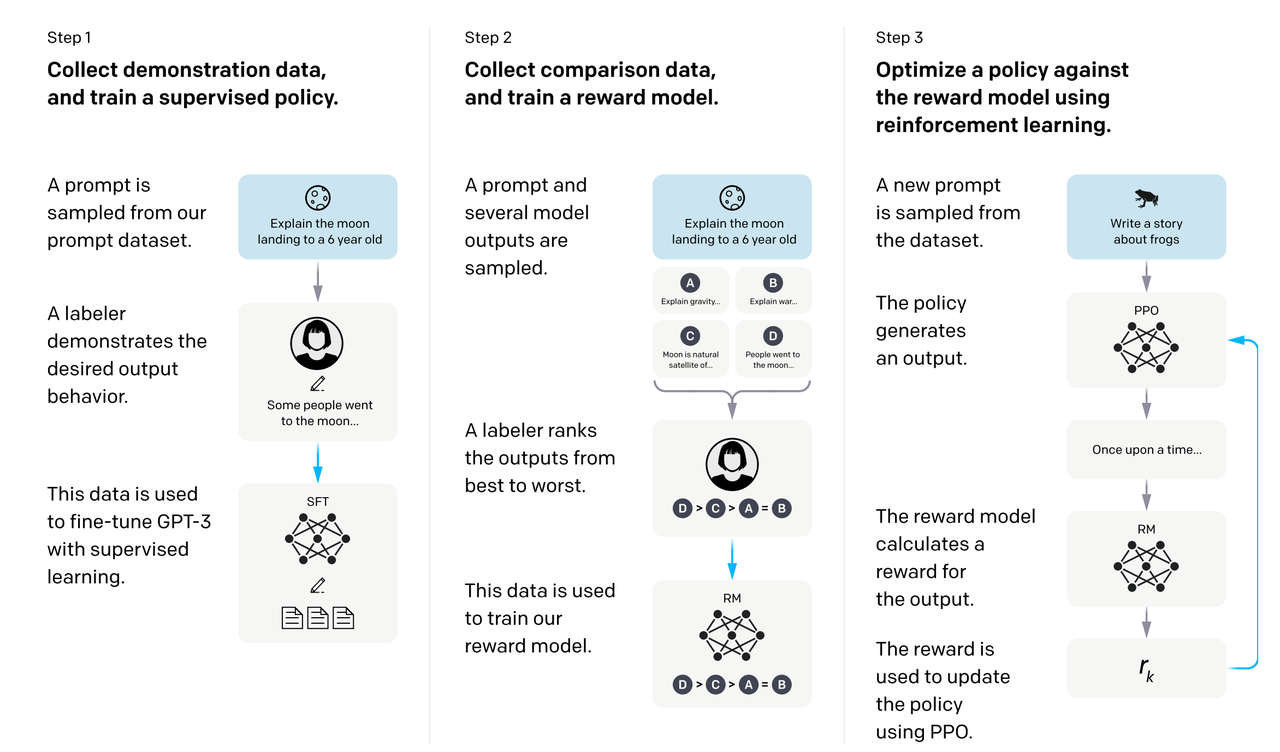
包括上面三个部分,SFT、RM、PPO(RLHF,Reinforcement Learning fromHuman Feedback)。
SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler),和pretrain是一样的。
RM结构是将SFT训练后的模型的最后的嵌入层去掉后的模型。它的输入是prompt和Reponse,输出是奖励值。具体的讲,对于每个prompt,InstructGPT会随机生成n个输出,然后它们向每个labeler成对的展示输出结果,也就是每个prompt共展示 $C_n^2$个结果,然后用户从中选择效果更好的输出。在训练时,将每个prompt的$C_n^2$个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。
$$
L = -\frac{1}{C_n^2}E_{(x,y_w,y_l)~D}[log(\sigma(r_\theta(x,y_w)-r_\theta(x,y_l)))]
$$
相当于是个ltr的loss,w=win,l=lose。
PPO数据没有进行标注,它均来自GPT-3的API的用户。有不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务,QA,头脑风暴,对话等。
RLHF-PPO
- Actor Model:就是我们想要训练的目标语言模型,需要训练
- Critic Model:预估总收益$ V_t$,需要训练
- Reward Model:计算即时收益 $R_t$,参数冻结
- Reference Model:它的作用是在RLHF阶段给语言模型增加一些约束,防止语言模型训歪,就是SFT模型,参数冻结
RLHF-PPO的训练过程
- 准备一个batch的prompts
- 将这个batch的prompts喂给Actor模型,让它生成对应的responses
- 把prompt+responses喂给Critic/Reward/Reference模型,让它生成用于计算actor/critic loss的数据,这些数据称为经验(experiences)。
- 根据这些经验,实际计算出actor/critic loss,然后更新Actor和Critic模型
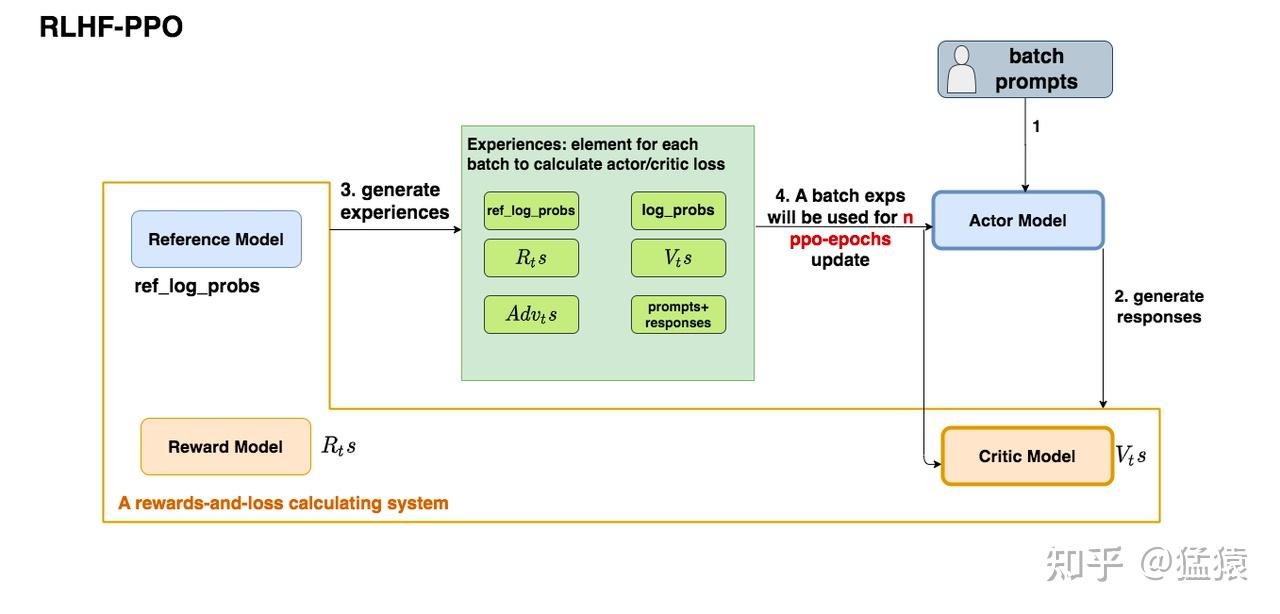
在强化学习中,收集一个batch的经验是非常耗时的。对应RLHF,收集一次经验,它要等四个模型做完推理才可以,因此,一个batch的经验,计算ppo-epochs次loss,更新ppo-epochs次Actor和Critic模型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 初始化RLHF中的四个模型
actor, critic, reward, ref = initialize_models()
# 训练, 对于每一个batch的数据
for i in steps:
# 先收集经验值
exps = generate_experience(prompts, actor, critic, reward, ref)
# 一个batch的经验值将被用于计算ppo_epochs次loss,更新ppo_epochs次模型
# 这也意味着,当你计算一次新loss时,你用的是更新后的模型
for j in ppo_epochs:
actor_loss = cal_actor_loss(exps, actor)
critic_loss = cal_critic_loss(exps, critic)
actor.backward(actor_loss)
actor.step()
critc.backward(critic_loss)
critic.step()
actor loss
$$
actor_loss = -min[Adv_t * \frac{P(A_t|S_t)}{P_{old}(A_t|S_t)}, Adv_t * clip(\frac{P(A_t|S_t)}{P_{old}(A_t|S_t)}, 0.8, 1.2)]
$$
其中
$$
Adv_t=(R_t+\gamma*V_{t+1}-V_{t})+\gamma * \lambda * Adv_{t+1}
$$
critic loss
$$
critic_loss = (R_t+\gamma*V_{t+1}-V_t)^2
$$
其中,$V_t$是Critic对t时刻的总收益的预估,这个总收益包含即时和未来的概念(预估收益),
$R_t+\gamma*V_{t+1}$是Reward计算出的即时收益$R_t$,Critic预测出的$t+1$及之后时候的收益的折现$V_{t+1}$,这是比
$V_t$更接近t时刻真值总收益的一个值(实际收益)
一个小注意点
最大化目标函数$J(\theta)=\mathbb{E}{\tau \sim \pi{\theta}}[R(\tau)]$。根据期望的定义,它可以写成:
$$
J(\theta)=\sum_{\tau} P(\tau \mid \theta) R(\tau) \tag{6}
$$
其中 $P(\tau \mid \theta)$ 表示参数 $\theta$ 下某条轨迹 $\tau$ 发生的概率,$R(\tau)$ 表示这条轨迹的总回报。
对它求梯度:
$$
\nabla_{\theta} J(\theta)=\nabla_{\theta} \sum_{\tau} P(\tau \mid \theta) R(\tau)=\sum_{\tau}\left(\nabla_{\theta} P(\tau \mid \theta)\right) R(\tau) \tag{7}
$$
这个形式不是一个期望,我们无法通过蒙特卡洛采样来估计它。而 $\tau$ 有无限种,我们无法穷举。
形如 $\mathbb{E}[f(X)]=\sum_{x} P(x) f(x)$ 的式子,我们可以通过从 $P(X)$ 中采样 $x_i$,然后用 $\frac{1}{N} \sum_{i} f(x_i)$ 来近似。
可以利用log导数的性质$\nabla_{\theta} P(\tau \mid \theta)=P(\tau \mid \theta) \nabla_{\theta} \log P(\tau \mid \theta)$
$$
\nabla_{\theta} J(\theta) = \sum_{\tau}\left(\nabla_{\theta} P(\tau \mid \theta)\right) R(\tau) \
=\sum_{\tau} P(\tau \mid \theta)\left[\left(\nabla_{\theta} \log P(\tau \mid \theta)\right) R(\tau)\right] \
= \mathbb{E}{\tau \sim \theta}\left[\left(\nabla{\theta} \log P(\tau \mid \theta)\right) R(\tau)\right]
$$
进一步可以证明,$\nabla_{\theta} \log P(\tau \mid \theta)=\sum_{t=0}^{T} \nabla_{\theta} \log \pi_{\theta}\left(a_t \mid s_t\right)$,这就是我们熟悉的策略梯度定理了。