记一点广告的基础知识
MLE和MAP
- MLE最大化$P(Y|X,\theta)$
- MAP最大化$P(\theta|X,Y) \propto P(Y|X,\theta)P(\theta)$
特殊情况:
- 如果$\theta$是均匀分布,两者等效
- 如果$P(\theta)$是高斯分布,等同于L2正则
- 如果$P(\theta)$是拉普拉斯分布,等同于L1正则
负采样纠偏
训练时纠偏,训练输出就是无偏结果,inference时不需要纠偏。
用采样后的样本,预测输出的logit为$f’$,无偏的结果为$f$,$p’=\frac{1}{1+e^{-f’}}$,$p$同理。
$$
p=\frac{p’}{p’+\frac{1-p’}{r}}
$$
这里$r$是负样本采样率,把$p$都替换成$f$,可以得到:
$$
f=f’+ln(r)
$$
注:模型auc需要用这种纠偏之后,才能对比。
Weighted LR
YouTube-DNN 时长建模,
参考:Deep Neural Networks for YouTube Recommendations
$$
-\sum_i [t_i y_i log(p_i) + (1-y_i) log(1-p_i)] \
p_i = \frac{1}{1+e^{-wz}} \
odds = \frac{P}{1-P} = e^{wz}=\frac{E(t)}{1-P}
$$
因为$P$比较小,所以$E(t)=e^{wz}$
如果把所有的样本都作为负例,对正样本加权,就不会有近似了,直接是无偏的。
LR概率模型分析
- 常见的LR:假设数据服从伯努利分布,发生概率为$p$,不发生为$1-p$,$odds=p/(1-p)$为几率比
- weighted LR:假设数据服从几何分布,假设用户看单位时长的概率为p,期望为$\frac{1}{1-p}-1=e^{wz}$(-1是因为几何概率一般是从1开始,我们这里是从0开始)
回归转分类
把连续值分桶,softmax预测在每个桶的概率,不需要对label有啥分布的假设。
可以对label做软化,默认分桶是01 hard label,可以类似知识蒸馏,对标签做软化,但实际上我们没有teacher model,可以依赖一些先验假设,比如高斯分布。
TPM
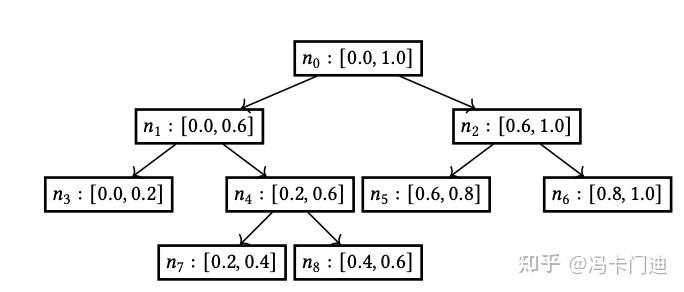
可以有级联的loss:softmax loss,每个桶内的连续loss。参考KDD23快手的TPM,Tree based Progressive Regression Model。
每个叶子节点是最后的分类,也对应了一条路径,每个叶子节点的概率是多层概率的乘积。
Ordinal regression
把学习目标送PDF改为CDF,也是把连续值分成$K$个桶。预测的不是属于某个桶的概率,而是小于等于某个桶的概率。
$$
F(k)=P(f(x_i)\le t_k)=\sigma(t_k-f(x_i))
$$
$$
f(k)=F(k)-F(k-1)
$$
但这里对分布有假设,$\sigma$是一个CDF,可以是sigmoid函数,或者高斯分布的CDF$\Phi$。
还有一种方法,是变成$K$个二分类。
ZILN loss
参考:ZILN论文(zero-inflated lognormal)
The ZILN loss can be similarly derived as the negative log-likelihood of a ZILN distributed random variable with p as the probability of being nonzero:
$$
L_{ZILN}(x; p, \mu, \sigma) = −1_{x=0} log(1 − p) − 1_{x>0}(log p − L_{Lognormal}(x; \mu, \sigma))
$$
where 1 denotes the indicator function.
The loss can be decomposed into two terms:
- 分类loss:判断客户是否为回头客
- 回归loss:预测重复购买客户的LTV
$$
L_{ZILN}(x; p, \mu, \sigma) = L_{CrossEntropy}(1_{x>0}; p) + 1_{x>0}L_{Lognormal}(x; \mu, \sigma)
$$
模型输出3个值,分别对应:$p$,$\mu$,$\sigma$
预估的LTV为:$p e^{\mu+\sigma^2/2}$
多目标建模
- MMOE
- ESMM
- DBMTL
双塔近似计算
参考:Efficient Training on Very Large Corpora via Gramian Estimation