diffusion模型基础
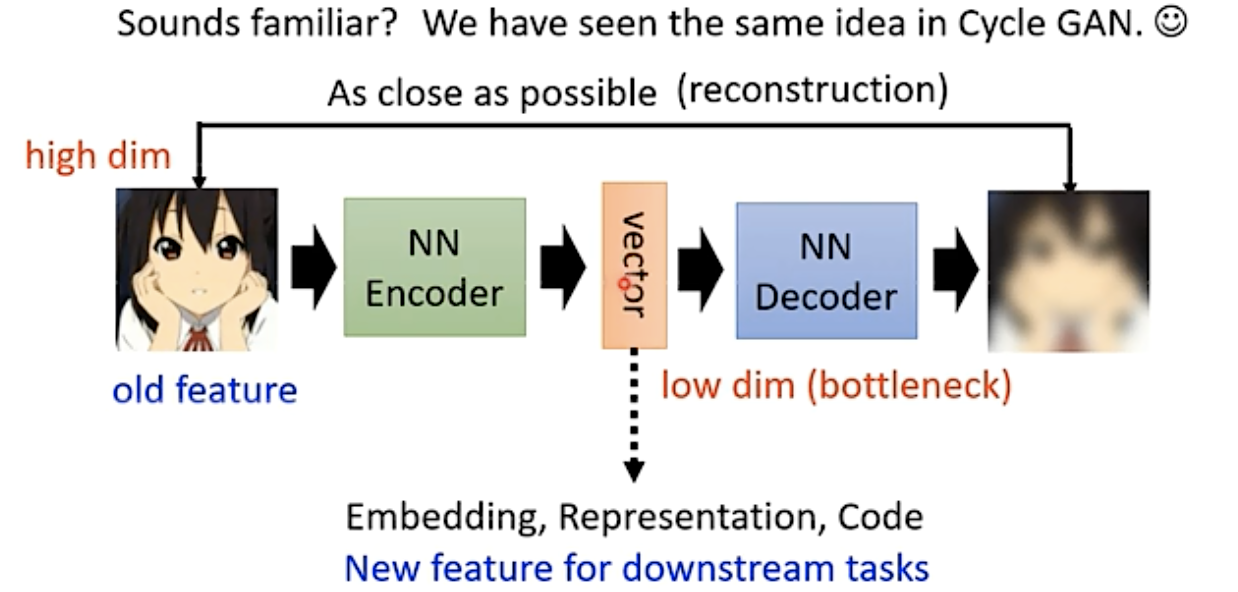
auto encoder
训练目标是:希望输入的图片经过两次转换和原来的图片越接近越好,也被称为“重构-reconstruction”(不需要有标签的数据)
常见的应用:原来的向量维度很高,经过encoder之后输出维度小的向量,再用这个低维度的向量去做后面的任务。
auto encoder严格来说不算生成模型,只是在重构,到VAE才算具备的生成能力。
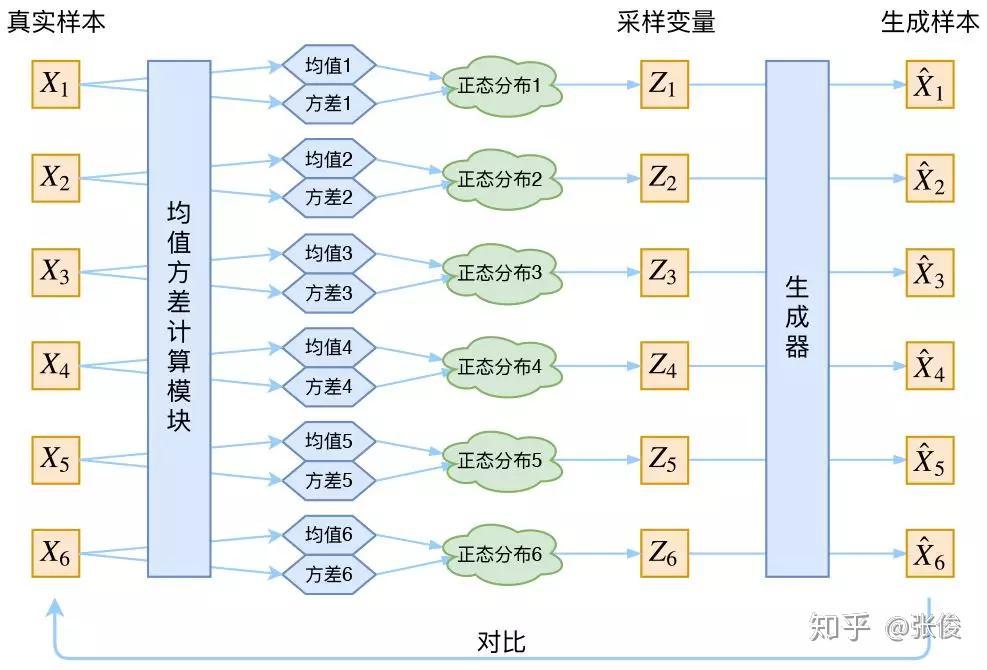
VAE(变分自编码器)
VAE 是一种概率生成模型,通过编码器将输入数据映射到潜空间,再通过解码器从潜空间重构数据。
在VAE中,我们假设$p(Z|X)$后验分布是正态分布,给定一个真实的样本$X_k$,都有专属的分布$p(Z|X_k)$。训练生成器时,采样一个$Z_k$来还原$X_k$。
VAE 的损失函数由两部分组成:
- reconstruction loss(重构损失):衡量重构输入 $\hat{X}$ 与原始输入 $X$ 的相似度,常用均方误差(MSE):
$$
\text{reconstruction loss} = | X - \hat{X} |^2
$$
其中 $\hat{X}$ 是解码器生成的重构结果。
- similarity loss(相似性损失):即 KL 散度,衡量潜在分布 $\mathcal{N}(\mu, \sigma)$ 与标准正态分布 $\mathcal{N}(0, I)$ 的差异,可以当做是一个正则项。
$$
\text{similarity loss} = D_{KL}(\mathcal{N}(\mu, \sigma) | \mathcal{N}(0, I)) \
=\frac{1}{2}(-log\sigma ^2+\mu ^2+\sigma ^ 2 - 1)
$$
VAE的训练过程本质上是重建损失和KL散度损失之间的权衡:重建损失希望编码器学习到区分度大、能精确重建的潜在表示,这可能倾向于让$\mu$分散、$\sigma$变小。KL散度损失则希望所有分布收缩到0和1,防止VAE退化成普通AE,失去生成新样本的能力。
$$
\text{loss} = \text{reconstruction loss} + \text{similarity loss}
$$
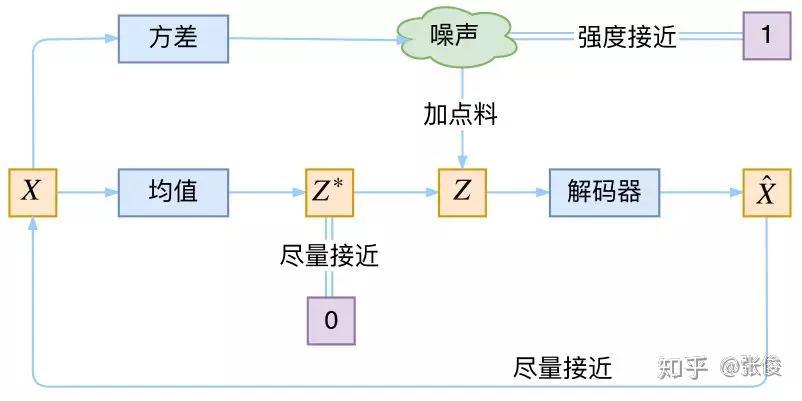
VAE存在一个固有问题,是用L2距离来衡量$\hat{X}$ 与 $X$ 的相似度,L2距离只是近似等于分布距离,会导致图片变得模糊(倾向于生成低频信号,这样L2 loss小)。
GAN(生成对抗网络)
GAN的思路是reconstruction loss不好衡量,我就用个模型来代替,多加了一个discriminator来判断图片是生成的还是真实的。训练过程是generator和discriminator交替进行。
我以前也写过GAN,当时GAN还很火。
$$
\min_G \max_D V(D,G) = E_{x \sim p_{\text{data}}(x)}[\log D(x)] + E_{z \sim p_{z}(z)}[\log(1 - D(G(z)))]
$$
这是生成对抗网络(GAN)的价值函数(Value Function)或目标函数(Objective Function)。
- $G$ 代表生成器(Generator),其目标是最小化这个函数($\min_G$)。
- $D$ 代表判别器(Discriminator),其目标是最大化这个函数($\max_D$)。
- $V(D, G)$ 是判别器 $D$ 和生成器 $G$ 之间的二人极小极大博弈的值。
公式组成部分:
$E_{x \sim p_{\text{data}}(x)}[\log D(x)]$:
- 这是判别器正确判断真实数据 $x$ 为真的期望。
- $p_{\text{data}}(x)$ 是真实数据分布。
- $D(x)$ 是判别器将真实数据 $x$ 判为真的概率。
- 判别器 $D$ 想要最大化这一项,使其接近 $1$($\log(1)=0$)。
$E_{z \sim p_{z}(z)}[\log(1 - D(G(z)))]$:
- 这是判别器正确判断生成数据 $G(z)$ 为假的期望。
- $p_{z}(z)$ 是噪声输入 $z$ 的先验分布。
- $G(z)$ 是生成器 $G$ 生成的假样本。
- $D(G(z))$ 是判别器将假样本 $G(z)$ 判为真的概率。
- 判别器 $D$ 想要最大化这一项,即使 $D(G(z))$ 接近 $0$($\log(1-0)=\log(1)=0$)。
- 生成器 $G$ 想要最小化这一项,即使 $D(G(z))$ 接近 $1$,从而骗过判别器。
Diffusion(扩散模型)
Diffusion 模型是一类基于概率扩散过程的生成模型。其核心思想是将数据逐步加噪声,最终变成纯噪声,然后训练一个模型学会如何一步步去噪,最终还原出原始数据。Diffusion 模型近年来在图像生成等任务上取得了极大成功,代表模型有 DDPM、Stable Diffusion 等。
Diffusion 模型包括两个过程:正向扩散过程(加噪声)和反向去噪过程(生成)。
1. 正向扩散(Forward Process)
正向过程将原始数据 $x_0$ 逐步加入高斯噪声,经过 $T$ 步后变成接近各向同性高斯分布的噪声 $x_T$。每一步的加噪过程如下:
$$
q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t I)
$$
其中 $\beta_t$ 是每一步的噪声强度。
2. 反向去噪(Reverse Process)
反向过程的目标是从纯噪声 $x_T$ 开始,逐步去噪,最终还原出数据 $x_0$。反向过程同样是高斯过程,但均值和方差需要模型学习:
$$
p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))
$$
训练时,通常用一个神经网络(如 U-Net)预测噪声或数据的均值。
Diffusion 模型的训练
Diffusion 模型的训练目标是让模型学会在每一步准确地去噪。常见的训练方式是让模型预测每一步加到数据上的噪声 $\epsilon$,损失函数为:
$$
L_{simple} = E_{x_0, \epsilon, t} \left[ | \epsilon - \epsilon_\theta(x_t, t) |^2 \right]
$$
其中 $x_t$ 是在 $t$ 时刻加噪后的数据,$\epsilon$ 是实际加的噪声,$\epsilon_\theta$ 是模型预测的噪声。
训练流程如下:
- 从数据集中采样一张图片 $x_0$。
- 随机采样一个时间步 $t$。
- 按照正向扩散公式加噪,得到 $x_t$。
- 用神经网络输入 $x_t$ 和 $t$,预测噪声 $\epsilon_\theta$。
- 计算损失并反向传播,更新模型参数。
Diffusion 模型的推理(采样)
推理阶段,从高斯噪声 $x_T$ 开始,利用训练好的模型逐步去噪,最终生成一张图片。每一步的采样过程如下:
- 初始化 $x_T \sim \mathcal{N}(0, I)$。
- 对 $t = T, T-1, …, 1$:
- 用模型预测当前噪声 $\epsilon_\theta(x_t, t)$。
- 计算 $x_{t-1}$ 的均值和方差。
- 从高斯分布采样 $x_{t-1}$。
- 最终得到 $x_0$,即生成的图片。
推理过程可以理解为“逆过程”,逐步将噪声还原为清晰的样本。采样步数越多,生成质量越高,但速度越慢。近年来也有很多加速采样的改进方法。