longcat video
LongCat-Video技术报告总结
美团LongCat团队发布的LongCat-Video,是一款参数规模达136亿的视频生成基础模型,核心目标是突破长视频生成的技术瓶颈,为世界模型(World Models)的构建奠定关键能力。该模型通过统一任务架构、优化长视频生成机制、提升推理效率及强化多奖励对齐,在文本转视频(Text-to-Video)、图像转视频(Image-to-Video)、视频续生(Video-Continuation)三大任务中表现优异,尤其能生成数分钟级、无色彩偏移与画质下降的长视频,相关代码与模型权重已开源(GitHub:https://github.com/meituan-longcat/LongCat-Video)。
一、核心背景与技术挑战
世界模型的核心是理解、模拟并预测复杂现实环境,而视频生成模型通过压缩几何、语义、物理等知识,成为构建世界模型的关键路径。当前视频生成领域虽有Veo(Google)、Sora(OpenAI)等商业模型及Wanx、HunyuanVideo等开源模型,但长视频生成仍面临两大核心挑战:
- 时序一致性缺失,生成误差随时间累积,导致长视频出现色彩漂移、动作断裂;
- 推理效率低下,高分辨率(如720p)、高帧率(如30fps)视频的注意力计算复杂度随token数量呈二次增长,难以平衡质量与速度。
二、模型核心设计与关键技术
1. 统一任务架构:单模型支持多任务
LongCat-Video基于扩散Transformer(DiT)框架构建,通过“条件帧数量区分任务类型”,实现三大任务的统一:
- 文本转视频(Text-to-Video):条件帧数量为0,仅依赖文本指令生成视频;
- 图像转视频(Image-to-Video):条件帧数量为1,基于单张参考图像生成动态视频;
- 视频续生(Video-Continuation):条件帧数量为多,基于已有视频片段续生长视频。
1 | ┌─────────────────────────────────────────────────────────────────────────┐ |
模型输入由“无噪声条件序列 $X_{cond} \in \mathbb{R}^{B \times N_{cond} \times H \times W \times C}$ 与待去噪噪声序列
$X_{noisy} \in \mathbb{R}^{B \times N_{noisy} \times H \times W \times C}$沿时间轴拼接而成,即:
$X=[X_{cond}, X_{noisy}]$
其中$N_{cond}$、$N_{noisy}$分别为条件帧与噪声帧长度,$B$为批次大小,$H$、$W$为空间维度,$C$为通道数。
同时,时间步$t$也对应划分为$t=[t_{cond}, t_{noisy}]$,$t_{cond}$固定为$0$以注入无损信息,$t_{noisy}$采样自$[0,1]$,训练时仅计算噪声序列的损失,确保任务区分与训练效率。
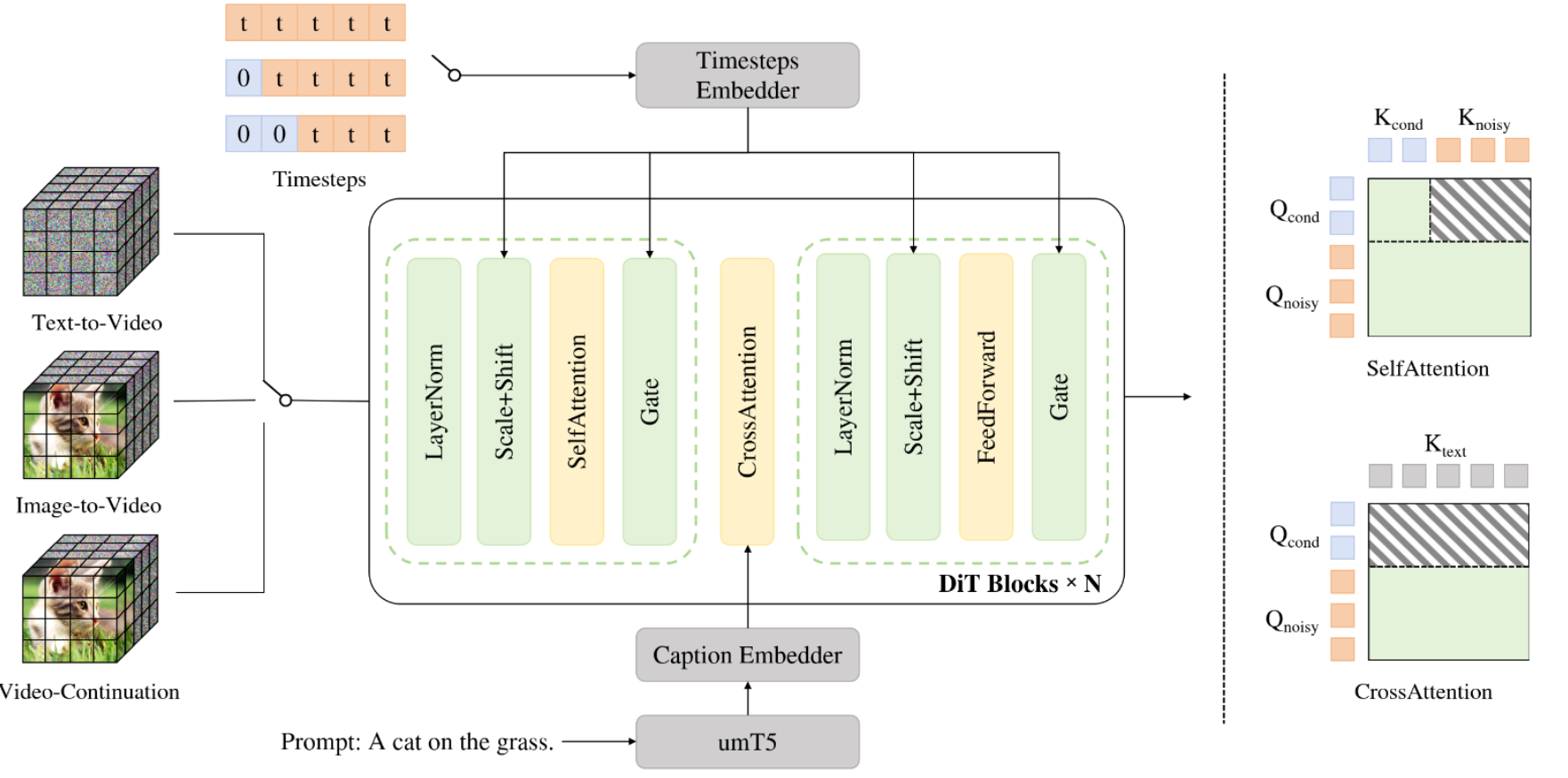
$$
X_{\text{cond}} = \text{Attention}\left(Q_{\text{cond}}, K_{\text{cond}}, V_{\text{cond}}\right)
\
X_{\text{noisy}} = \text{Attention}\left(Q_{\text{noisy}}, \left[K_{\text{cond}}, K_{\text{noisy}}\right], \left[V_{\text{cond}}, V_{\text{noisy}}\right]\right)
$$
2. 长视频生成:视频续生预训练与时序一致性保障
为解决长视频生成的误差累积问题,模型未采用“微调现有基础模型”的常规思路,而是原生基于视频续生任务预训练:通过学习“基于已有视频片段预测后续帧”的能力,天然具备长时序建模能力,可生成数分钟级视频且无质量退化。
同时,模型在注意力机制中引入“块注意力与 KVCache”:条件帧的注意力计算仅依赖自身,噪声帧的注意力则结合条件帧与自身的键值对,具体表示为下面的展示公式:
$$
X_{\mathrm{cond}}=\mathrm{Attention}\left(Q_{\mathrm{cond}},;K_{\mathrm{cond}},;V_{\mathrm{cond}}\right)
$$
$$
X_{\mathrm{noisy}}=\mathrm{Attention}\left(Q_{\mathrm{noisy}},;[K_{\mathrm{cond}},;K_{\mathrm{noisy}}],;[V_{\mathrm{cond}},;V_{\mathrm{noisy}}]\right)
$$
这种设计既避免条件帧受噪声干扰,又能通过缓存条件帧的 KV 特征复用计算,保障长视频生成的时序连贯性。
3. 高效推理:粗精生成与块稀疏注意力
为降低高分辨率视频的推理成本,模型采用两大优化策略:
粗到精(Coarse-to-Fine)生成:先生成480p、15fps的低分辨率视频,再通过三线性插值 upscale 至720p、30fps,并由LoRA训练的精修专家模型优化细节。精修阶段基于流匹配(Flow Matching)建模低分辨率与高分辨率视频分布的映射,输入噪声帧定义为:
$$
x_{t’} = x_{0} + (x_{thresh} - x_{0}) \cdot \frac{t’}{t_{thresh}},\qquad t’\in[0,,t_{thresh}]
$$其中
$$
x_{thresh} = (1 - t_{thresh})\cdot x_{up} + t_{thresh}\cdot \epsilon,\qquad \epsilon \sim \mathcal{N}(0,I)
$$说明:x_{up} 为低分辨率视频上采样后的 latent 特征;t_{thresh} 通常设为 0.5,以在噪声注入与细节保留之间取得平衡。精修阶段基于此噪声调度仅需约 5 步采样完成细节恢复与增强。
三、训练数据与评估
1. 数据筛选与标注
模型构建了“数据预处理-标注”全流程 pipeline:预处理阶段通过多源采集、MD5去重、PySceneDetect+TransNetV2分割视频、FFmpeg裁剪黑边,得到有效片段;标注阶段则标注基础元数据(时长、分辨率)、质量指标(美学评分、模糊度)、运动信息(光流)及文本描述(基于微调的LLaVA-Video生成多风格字幕),形成支持多阶段训练的元数据库。
2. 评估结果
- 内部基准:在1628个样本的测试集中,文本转视频任务的“视觉质量”评分接近Wan2.2,“整体质量”超越PixVerse-V5与Wan2.2;图像转视频任务的“视觉质量”(3.27分)排名第一,但“图像对齐”需进一步优化。
- 公共基准:VBench 2.0总得分(62.11%)仅次于Veo3(66.72%)与Vidu Q1(62.70%),“常识性”维度(70.94%)领先所有模型。