path_root = './_posts/' files = os.listdir(path_root) files = [path_root + x for x in files if x.endswith('.md')] insert_line = 'typora-root-url: ../../source'
for file in files: withopen(file) as f: lines = f.readlines()
ifany([insert_line in x for x in lines]): continue
var gulp = require('gulp'); var minifycss = require('gulp-clean-css'); var uglify = require('gulp-uglify'); var htmlmin = require('gulp-htmlmin'); var htmlclean = require('gulp-htmlclean'); var imagemin = require('gulp-imagemin'); var del = require('del'); var runSequence = require('run-sequence'); varHexo = require('hexo');
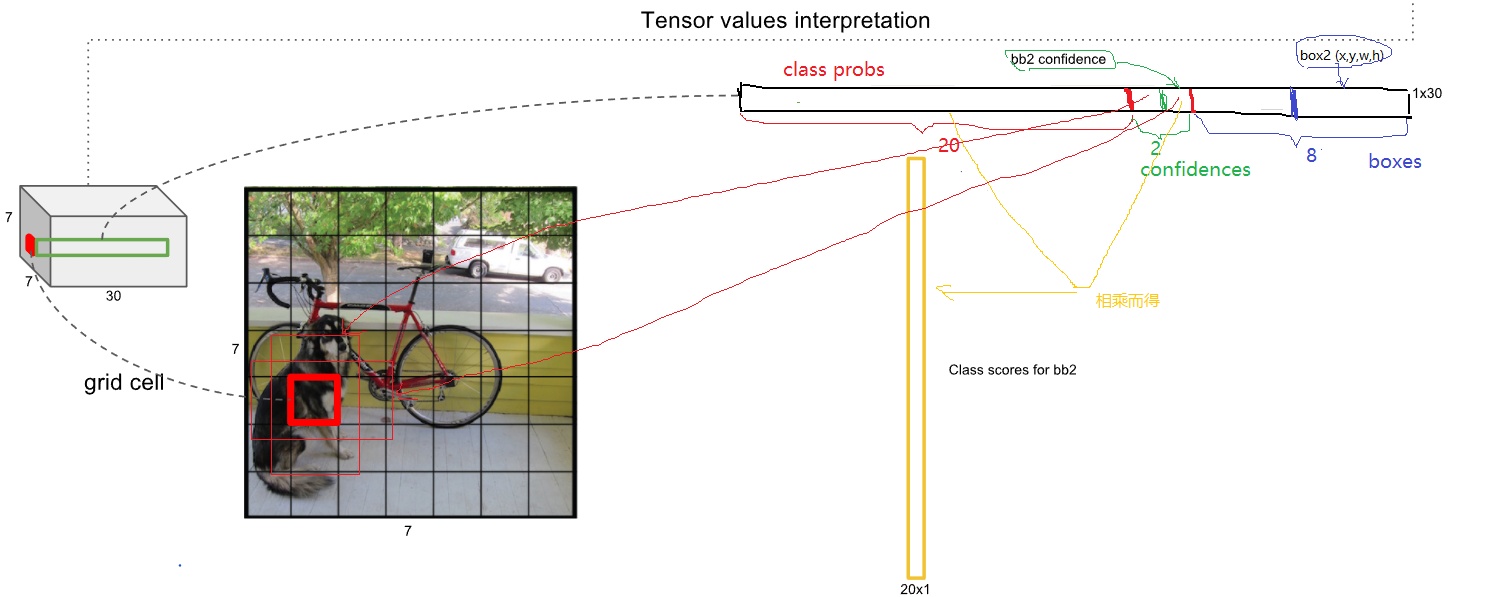
主要变量是Pb和Pnb,Pb[t][l], is the probability that a prefix, l, at a specific time step, t, originates from one or more paths ending in the blank token
think of a language model as a function taking a sentence as input, which is often only partly constructed, and returning the probability of the last word given all the previous words.
from collections import defaultdict, Counter from string import ascii_lowercase import re import numpy as np
defprefix_beam_search(ctc, lm=None, k=25, alpha=0.30, beta=5, prune=0.001): """ Performs prefix beam search on the output of a CTC network. Args: ctc (np.ndarray): The CTC output. Should be a 2D array (timesteps x alphabet_size) lm (func): Language model function. Should take as input a string and output a probability. k (int): The beam width. Will keep the 'k' most likely candidates at each timestep. alpha (float): The language model weight. Should usually be between 0 and 1. beta (float): The language model compensation term. The higher the 'alpha', the higher the 'beta'. prune (float): Only extend prefixes with chars with an emission probability higher than 'prune'. Retruns: string: The decoded CTC output. """
lm = (lambda l: 1) if lm isNoneelse lm # if no LM is provided, return 1 W = lambda l: re.findall(r'\w+[\s|>]', l) alphabet = list(ascii_lowercase) + [' ', '>', '%'] F = ctc.shape[1] ctc = np.vstack((np.zeros(F), ctc)) # just add an imaginative zero'th step T = ctc.shape[0]
# STEP 1: Initiliazation O = ''# means empty Pb, Pnb = defaultdict(Counter), defaultdict(Counter) Pb[0][O] = 1# balnk prob is 1 Pnb[0][O] = 0# non blank prob is 0 A_prev = [O] # END: STEP 1
# STEP 2: Iterations and pruning for t inrange(1, T): pruned_alphabet = [alphabet[i] for i in np.where(ctc[t] > prune)[0]] for l in A_prev: # A_prev is a string list iflen(l) > 0and l[-1] == '>': # < means end-character Pb[t][l] = Pb[t - 1][l] Pnb[t][l] = Pnb[t - 1][l] continue
for c in pruned_alphabet: c_ix = alphabet.index(c) # END: STEP 2 # STEP 3: “Extending” with a blank if c == '%': # % means blank, index is -1 Pb[t][l] += ctc[t][-1] * (Pb[t - 1][l] + Pnb[t - 1][l]) # END: STEP 3 # STEP 4: Extending with the end character else: l_plus = l + c iflen(l) > 0and c == l[-1]: Pnb[t][l_plus] += ctc[t][c_ix] * Pb[t - 1][l] Pnb[t][l] += ctc[t][c_ix] * Pnb[t - 1][l] # END: STEP 4
# STEP 5: Extending with any other non-blank character # and LM constraints # eliflen(l.replace(' ', '')) > 0and c in (' ', '>'): lm_prob = lm(l_plus.strip(' >')) ** alpha Pnb[t][l_plus] += lm_prob * ctc[t][c_ix] * (Pb[t - 1][l] + Pnb[t - 1][l]) else: Pnb[t][l_plus] += ctc[t][c_ix] * (Pb[t - 1][l] + Pnb[t - 1][l]) # END: STEP 5
# STEP 6: Make use of discarded prefixes # 可能l_plus已经存在过,但在上一步的时候扔掉了,这里相当于补回来 if l_plus notin A_prev: Pb[t][l_plus] += ctc[t][-1] * (Pb[t - 1][l_plus] + Pnb[t - 1][l_plus]) Pnb[t][l_plus] += ctc[t][c_ix] * Pnb[t - 1][l_plus] # END: STEP 6
后来想起来,sequence to sequence都有beam search和 greedy search,但是只是CTC的softmax是fram synchronously,所以逻辑才比较复杂,所以Attention一样也可以用beam search。
Advanced Joint CTC-Attention
还是那几个作者的文章,升级版,Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM。
训练的过程没有做修改,还是CTC和Attention一起训练。
预测解码的时候修改了,以前是只用Attention,现在需要两个结合起来,用beam search做。但beam search有一个问题,Attention的softmax是character synchronously的,而CTC的是fram synchronously,并不是能很好地对应起来。 $$ \alpha_{att}(g_l)=\alpha_{att}(g_{l-1})+log(p(c|g_{l-1},X)) $$ Attention的概率这么计算,$c$ is the last character of $g_l$。