正则
- 这里占个坑
- 我想些反向搜索,但是我自己都没搞懂
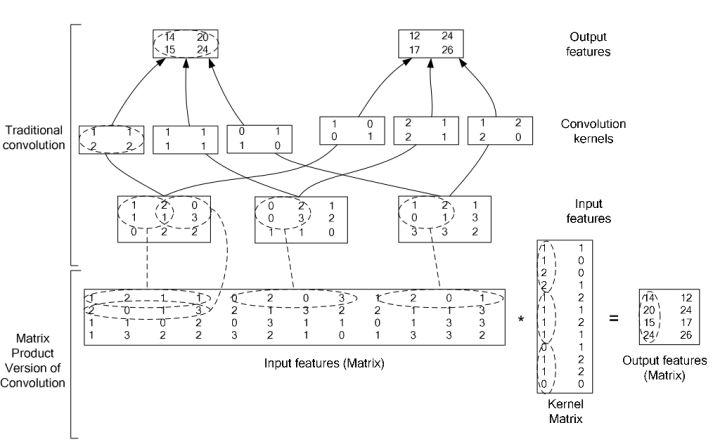
假设cnn之后,feature map是$T\times1$,用$x$表示,这里用caffe的表示方法,宽度在前,高度在后,忽略了batch size
Content Attention是最常见的Attention,计算权重只用到了$x$和LSTM的输出$c_{t-1}$,$c_{t-1}$和$x$都需要一个全连接
其实这里的$\hat{e}{t,j}, j=1..T$是一起算的,$wx$的shape已经是$T\times C$,而$wc{t-1}$是$1\times C$,需要扩增到$T\times C$
$$
\hat{e}{t,j}=wc{t-1}+wx_j \
e_{t,j}=tanh(\hat{e}{t,j}) \
\alpha{t,j}=softmax(we_{t,j})
$$
$\alpha_t$的shape是$T\times1$,是$x$每个位置的权重,然后进行累加,$g_t$称之为glimpse向量,
$$
g_t=\sum_{j=1}^{T}\alpha_{t,j}x_j
$$
然后用LSTM解码,这里$y_{t-1}+g_t$其实是不能直接加到,shape不一致,需要先对$y_{t-1}$全连接一下
$$
c_t,h_t=LSTM(y_{t-1}+g_t, c_{t-1}) \
y_t=argmax(softmax(wh_t))
$$
Content有一个严重对问题是计算权重对时候,只用到了内容信息,没有用到位置信息,所以会出现对不齐对问题
Hybrid Attention其实是Content Attention和Locate Attention的混合,区别只是体现在$\hat{e}_{t,j}$的计算上多了上一时刻的位置信息
$$
\hat{e}{t,j}=wc{t-1}+wx_j+w\alpha_{t-1,j}
$$
$\alpha_{t-1,j}$的shape是$T\times N\times1$,先换成$N\times T\times1$,然后用$1\times1$的卷积,卷成$N\times T\times C$,然后可以全连接,最后再换回$T\times N\times C$,这样就能加起来了
1 |
|
其中,__VA_ARGS__是参数...的展开
以此类推,三个参数的重载也是能实现的
1 |
|
explict,显示构造函数,只对构造函数有用,用来抑制隐式转换
1 | class String { |
template
1 | // suppose I've declared |
iniline主要是将代码进行复制,扩充,会使代码总量上升,好处就是可以节省调用的开销,能提高执行效率
shared_ptr引用计数智能指,可以参考这里
step1: 命令行下输入./build/tools/caffe train -solver xxx.prototxt 运行了程序的入口caffe.cpp main()
step2: caffe.cpp main()根据命令行输入的参数train 调用caffe.cpp train()
step3: caffe.cpp train()读取xxx.prototxt的参数 调用solver.cpp Solver()的构造函数创建Solver对象
step4: 创建Solver对象的时候需要调用solver.cpp Init()函数来初始化模型的网络
step5: solver.cpp Init()函数调用solver.cpp InitTrainNet()和InitTestNets()函数来分别初始化训练和测试网络。
step6: InitTrainNet() 通过xxx.prototxt 指定的xxxnet.prototxt读取net的参数,调用net.cpp Net()的构造函数,创建训练网络,
step7: net.cpp Net()调用net.cpp Init()函数,通过for循环来1)创建网络中每一个Layer对象,2)设置bottom和top,3)调用layer.cpp Setup(),Setup()里会调用具体layer的LayerSetUp()和Reshape()
step8: 调用InitTestNets()创建测试网络,与InitTrainNet()类似
step9: 运行返回到caffe.cpp train()中,利用创建好的solver对象调用solver.cpp Solve()函数
step10: solver.cpp Solve() 调用 solver.cpp Step()函数,while循环迭代的次数,每次迭代 1)调用net.cpp ForwardBackward()来前向以及后向传播 2)solve.cpp ApplyUpdate()更新参数 3)每一定轮次运行solver.cpp TestAll()
caffe.cpp中的main()调用train(),train()中创建solver对象,solver对象初始化会调用solver.cpp中的Init()
Init()中,创建InitTrainNet()和InitTestNet()
返回到caffe.cpp的train()中,调用Solver()来训练网络,具体过程在solver.cpp的Step()中实现
以上抄自这里
#define B(x) #@x,则B(a)即’a’,B(1)即’1’1 |
|

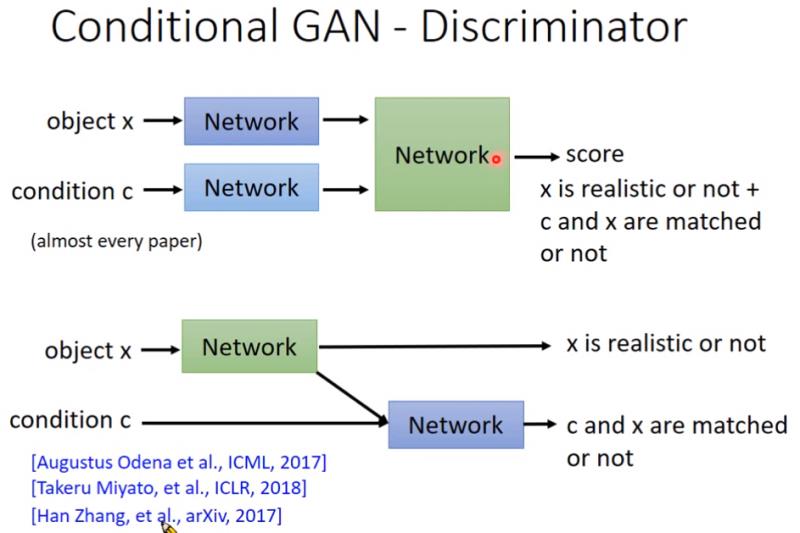
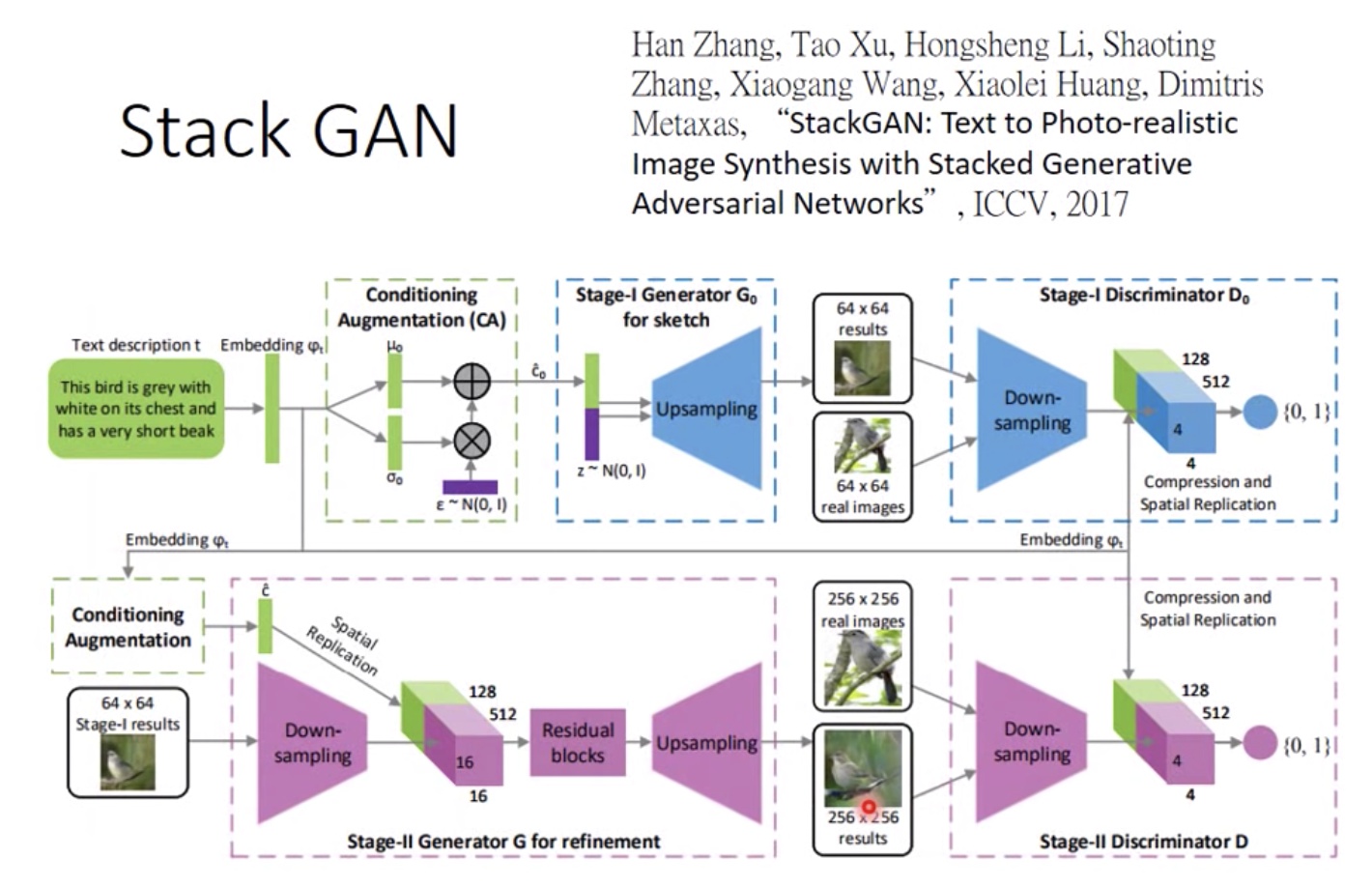
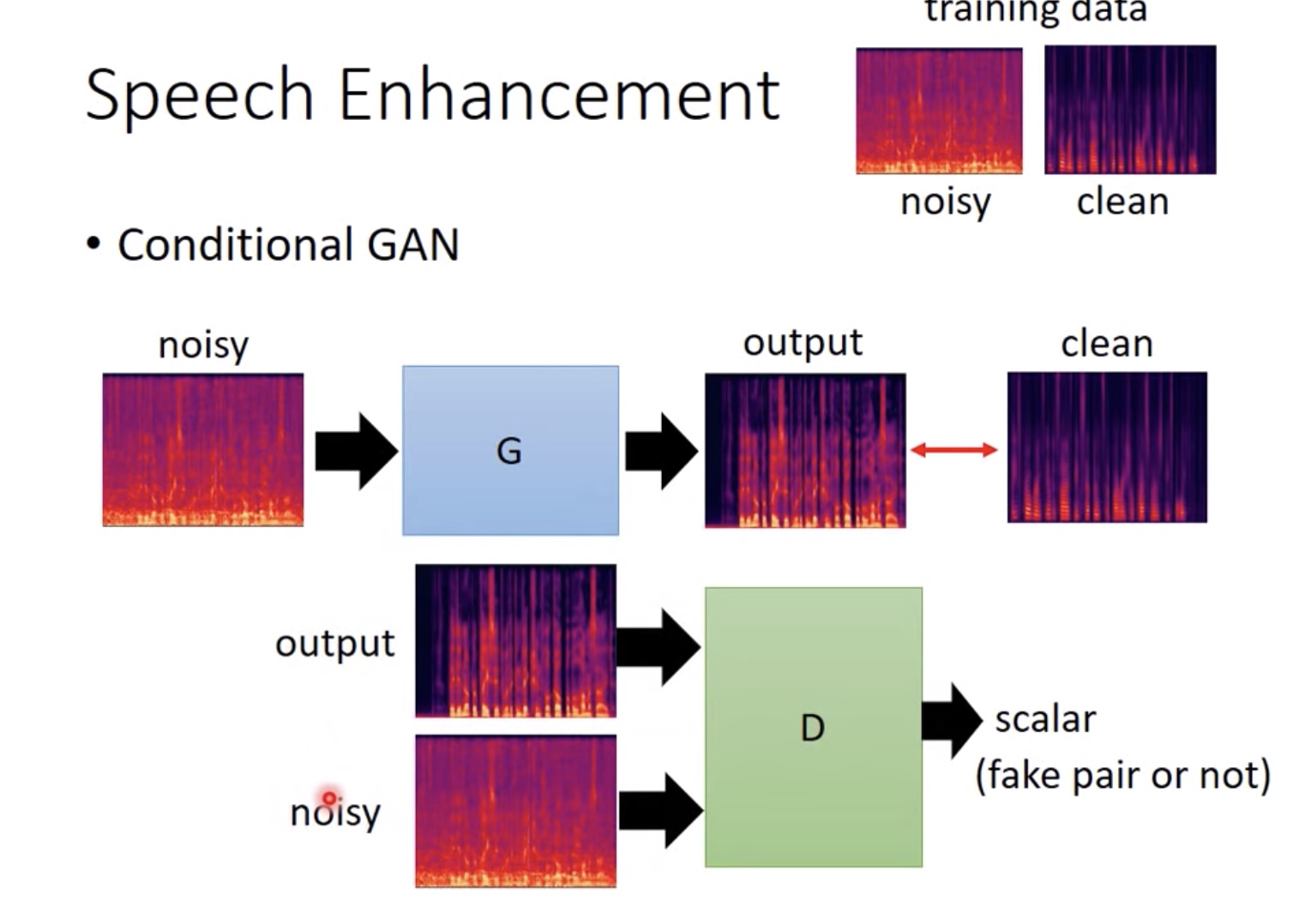
机器之心的这篇,基本就是照着李宏毅对课件写的,可以主要看一下为什么说判别器可以衡量两个分布之间的JS散度
GAN的过程

In practice, equation 1 may not provide sufficient gradient for G to learn well. Early in learning,
when G is poor, D can reject samples with high confidence because they are clearly different from
the training data. In this case, log(1 − D(G(z))) saturates. Rather than training G to minimize
log(1 − D(G(z))) we can train G to maximize log D(G(z)). This objective function results in the
same fixed point of the dynamics of G and D


![]()
![]()
1 | for file in `ls /etc` |
1 | if condition |
1 | case "$varname" in |
1 | source ./function.sh |
1 | string="abcd" |
1 | arr=(1 2 3 4 5) |
1 | a=10 |
/dev/null是个空文件,清空一个文件可以用cat /dev/null > tmp.log,不想保存log,也不想输出到屏幕,可以1>/dev/null 2>&1: > tmp.log,:是个内建命令,什么也不做,永远返回01 | : |
cp t.{txt,back} 文件名扩展1 | a=123 |
sudo sh -c "...",引号里的内容都会有sudo权限
echo $(( 2#101011 )),这里是2进制的意思
trap
1 | trap "echo Booh!" SIGINT SIGTERM |
1 | import requests |
照抄的这里
1 | \{n,m\}, x\|y #bres需要写转义, |
1 | \d, \D, \S, \s |
-i后面是1 | sed -i '' 's/http.*ot0uaqt93.bkt.*\//\/images\//g' `ls *.md` |
1 | conda create -n your_env_name python=x.x anaconda |
最后的anaconda可选,有的话,会安装很多包,numpy、sklearn等等
1 | source activate your_env_name |
1 | conda install -n your_env_name [package] |
1 | source deactivate |
1 | conda env list |
1 | conda remove -n your_env_list -all |
1 | conda -v |
1 | conda update conda |
Python 项目管理从传统的 pip 演进到 Conda 或 UV 等现代工具,主要围绕解决环境隔离、依赖冲突、以及依赖关系的可维护性等痛点展开。
以下是基于提供的资料,梳理的 Python 项目管理现代化的演进过程和主要流派:
Python 在诞生之初,并未考虑工程结构的问题,导致早期的管理相当“放自我”。官方的 pip 规范一直在努力打补丁。
pip install flask 等命令会将库安装到一个全局环境中,被计算机上所有 Python 项目共享。为了解决版本和依赖冲突,设计出了虚拟环境(Virtual Environment)。
python -m venv .venv 命令创建虚拟环境。激活环境后,再使用 pip 安装库,这些库就会被安装到该项目的虚拟文件夹中,从而避免冲突。sys.path 变量来实现。激活环境后,虚拟目录会被添加到这个搜索列表里,确保 Python 在导入模块时能够成功加载安装在虚拟环境路径中的库。解决了环境隔离后,新的问题是如何方便准确地将项目的依赖列表分享给其他人,以便复现环境。
pip freeze 命令,将当前虚拟环境中所有已安装包及其确切版本号输出到一个文件,通常命名为 requirements.txt。接收方只需执行 pip install -r requirements.txt 即可安装依赖。pip freeze 无法区分项目真正需要的直接依赖(Direct Dependency)和这些直接依赖引入的间接依赖(Indirect Dependency)。如果项目复杂,情况很快会失控。pip 在卸载包时也无法很好地处理依赖关系。如果卸载了某个包(如 Flask),那些因为 Flask 而被安装的间接依赖仍会留在环境中,成为无人管理的孤儿依赖。现代 Python 项目的标准解决方案是使用 pyproject.toml 文件。
pyproject.toml 是官方指定的统一配置文件。在此之前,不同的开发工具(如类型检查器 mypy、测试框架 pytest)通常使用各自独立的配置文件,导致根目录下配置零散。如今,绝大多数主流工具都支持了 pyproject.toml。pyproject.toml 中,开发者只需在 dependencies 列表中声明项目的直接依赖即可。如果将来要删除某个依赖,只需删除配置文件中对应的一行,就不会留下任何孤儿依赖。pip install . 命令来安装。这条命令在背后做了两件事:首先是构建,将当前项目打包成标准 Python 软件包;其次是安装,自动把所有声明的依赖一并安装进来。site-packages 目录导致代码修改无法同步,通常需要加上 -e 参数,使用 pip install -e . 进行可编辑安装。纯手工维护 pyproject.toml 的流程存在痛点,例如无法再用简单的 pip install 命令添加新依赖,每次添加都需要手动查找名称和版本号并编辑配置,过程繁琐且容易出错。
venv 和 pip 的高级封装。它们在底层仍使用 venv 和 pip,但提供了更简单、更统一的接口。uv add flask 一条命令,就能自动修改 pyproject.toml(添加依赖声明)、自动创建 venv 虚拟环境,并将该包及其所有间接依赖安装到环境中。协作者只需执行 uv sync,即可自动读取配置文件、搭建环境并安装所有依赖。uv run 命令,可以在虚拟环境的上下文中执行命令,无需手动激活环境。与官方 Python 体系并行的是 Conda 宇宙,这是一个从设计之初就考虑周全的跨语言开发平台。